RFID (Radio Frequency IDentification)
Gestion de collisions - Introduction
Définition
Lorsqu'une station de base communique avec plusieurs transpondeurs présents dans son champ magnétique, les messages émis par chacun des tags sont susceptibles de se heurter. La superposition de signaux fréquentiels revient à sommer ces signaux en amplitude. Vous comprendrez logiquement que le mélange des signaux provoquent des conflits et rend la distinction de chaque message difficile pour la station de base. C'est ce que l'on appelle des collisions.
Pour palier ce problème, de nombreux dispositifs intègrent des outils qui permettent de gérer les collisions. En effet, comme nous l'avons mentionné précédemment, les stations de base possèdent des circuits de gestion de la communication. Elles peuvent notamment intégrer des algorithmes anticollisions.
Causes des collisions
Plusieurs phénomènes ou cas de figure sont à l'origine des collisions fréquentielles en RFID parmi lesquelles les plus courantes sont :
- le "tag stack" : en français, cela signifie la "pile de tags". Dans ce cas de figure, plusieurs tags sont empilés les uns sur les autres ou, tout du moins, suffisamment proches les uns des autres. Lorsque la station de base communique avec l'un des transpondeurs, elle est susceptible de fournir de l'énergie à tous les transpondeurs par téléalimentation et d'entrer en communication avec eux. Cela pose évidemment des problèmes d'interférences. Par exemple : les forfaits de ski sont équipés de la technologie RFID et l'on vous conseille généralement de placer ce pass isolément dans une poche, ceci afin d'éviter qu'il se dé-magnétise. Les trois cas classiques de tag stack sont : un porte-feuille contenant plusieurs cartes à puce sans contact, les piles de lettres recommandées équipées de tags et les piles de jetons de casino intégrant des tags (cela existe pour certains jeux).
- les "weak collisions" : elles désignent les collisions de faibles signaux. Ce cas de figure survient notamment lorsque plusieurs transpondeurs sont placés de façon éloignée dans un champ magnétique assez vaste. Les signaux fréquentiels réfléchis vers la station sont atténués par la distance et la collision des messages est donc plus difficile à identifier. De plus, si les signaux sont trop faibles, ils sont plus difficiles à distinguer du bruit fréquentiel.
- l'absorption magnétique : ce phénomène se caractérise par la situation "un transpondeur peut en cacher un autre". Supposons qu'un transpondeur relativement proche de la station de base soit placé entre cette station et un tag beaucoup plus éloigné. Alors, les signaux du transpondeur le plus éloigné, faibles devant ceux du transpondeur le plus proche, seront "absorbés" par ceux du tag placé sur son chemin. Cette absorption est susceptible de générer des collisions.
Exemples de collisions
Voici deux exemples de collisions :

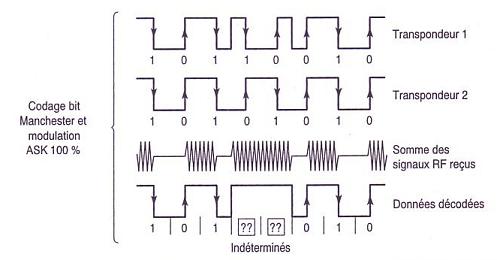
Dans le cas du premier exemple, le codage des données en signal fréquentiel utilisé est le codage NRZ et la modulation utilisée pour transmettre le message est une modulation d'amplitude (ASK). Les transpondeurs 1 et 2 diffusent leurs messages respectifs à la station de base. Les signaux fréquentiels sont alors superposés et la station de base reçoit et décode ce message. Par collision, les données reçues ne correspondent ni à celles provenant du transpondeur 1, ni à celles provenant du transpondeur 2. On conclut donc à des erreurs.
Dans le cas du second exemple, le codage des données en signal fréquentiel utilisé est le code Manchester et la modulation utilisée pour transmettre le message est une modulation d'amplitude (ASK). Les transpondeurs 1 et 2 diffusent leurs messages respectifs à la station de base. Les signaux fréquentiels sont alors superposés et la station de base reçoit et décode ce message. Par collision, les données reçues ne correspondent à aucun des deux messages initiaux. De plus, au niveau de la collision, la superposition des informations ne constitue pas des transitions milieu de bit. Le format des données obtenues au niveau de la collision ne correspond donc pas à un message codé en Manchester. On conclut donc à des états indéterminés.
Ce dernier exemple soulève donc un point important. En effet, dans les deux cas de collision, les données récupérées ne correspondent à aucun des deux messages que la station de base attendait. Néanmoins, dans le premier cas, les états obtenus par collision sont des états cohérents ('0' ou '1'). Dans le second cas, la collision génère des états qui ne sont pas définis dans le code Manchester (pas de transition milieu de bit). C'est là un point intéressant que nous avions déjà évoqué dans l'étude des codages utilisés. Nous constatons que le code Manchester possède cet avantage de pouvoir distinguer plus facilement les collisions, grâce à la présence d'états indéterminés. C'est une des raisons pour lesquelles, le code couramment utilisé dans les liaisons descendantes est le code Manchester. Cela est d'autant plus important que, de par cette particularité, il est possible d'effectuer des corrections bit à bit en code Manchester. Il existe pour cela des algorithmes qui sont utilisés par les algorithmes anticollisions.
Méthodes de gestion des collisions
Pour palier les problèmes de collisions, il existe différents types d'algorithmes. Ces algorithmes s'appuie sur des techniques de gestion de collisions variées :
- fréquentielle : la plage fréquentielle utilisée par le dispositif RFID est divisée en plusieurs canaux fréquentiels. Chaque canal de bande passante est alors alloué à un transpondeur spécifique et sera utilisé par la station de base pour communiquer avec ce tag uniquement,
- spatiale : la station de base analyse l'espace de son champ magnétique par petites parcelles. Cela diminue considérablement la probabilité de détecter plusieurs transpondeurs simultanément car l'espace "scanné" est très réduit. Cette technique permet donc d'identifier chaque transpondeur isolément, en réduisant les possibilités de collisions.
- temporelle : de la même manière que pour la gestion fréquentielle, cette technique permet de mettre en place une gestion temporelle des communications. Des slots de temps d'une certaine durée sont établis et utilisés périodiquement. Chaque slot est alors dédié à la communication avec un transpondeur particulier.
Les méthodes utilisées pour gérer les collisions en RFID reposent sur deux types d'algorithmes :
- les algorithmes déterministes : dont le but est d'identifier chaque transpondeur par son UID (Unique IDentifier) de façon certaine et le plus rapidement possible. Cette méthode peut s'avérer longue mais est complétèment déterminée. Les temps pour sélectionner les transpondeurs sont calculables et nous sommes certains, au final, d'identifier tous les transpondeurs de proche en proche. Ceci afin de pouvoir établir des dialogues individuels et donc limiter les risques de collisions.
- les algorithmes probabilistes : qui sont plus efficaces que leurs prédecesseurs lorsque le codage bit et les effets de masquage provoquent des collisions niveau bit plus difficiles à détecter. Ils sont utiles contre les pollutions radiofréquence. Cependant, tout n'est pas déterminable et calculable avec ces méthodes probabilistes. Les algorithmes fonctionnent de proche en proche.
Nous nous proposons donc d'analyser un type d'algorithme déterministe et un type d'algorithme probabiliste.