 Philippe Gambette -
LIGM, bureau 4B079 - +33 (0)1 60 95 77 34
Philippe Gambette -
LIGM, bureau 4B079 - +33 (0)1 60 95 77 34
TreeCloud est programmĂŠ en Python. Il faut donc commencer par installer Python 2.7.6 (Windows x86 MSI Installer) en le tĂŠlĂŠchargeant Ă cette adresse.
Pour construire et afficher les arbres, TreeCloud utilise SplitsTree. Il faut donc installer SplitsTree en tÊlÊchargeant la version 4.10 (pas la dernière version !). SplitsTree Êtant programmÊ en Java, si vous n'avez pas Java sur votre ordinateur, il faut aussi le tÊlÊcharger.
Il reste maintenant Ă installer Treecloud. Pour cela, il faut tĂŠlĂŠcharger ce fichier Treecloud1.4.2beta.zip, puis le dĂŠcompresser dans un dossier du disque dur dont l'adresse ne contient pas d'espace, par exemple C:\Treecloud\.
Double-cliquez sur le programme TreeCloud.exe dans le dossier oĂš vous avez dĂŠcompressĂŠ le fichier zip tĂŠlĂŠchargĂŠ ci-dessus.
La fenĂŞtre principale de TreeCloud s'ouvre. Il faut commencer par configurer le programme en remplissant les champs Emplacement de Python (par exemple C:\Python27\python.exe, Ă adapter selon votre configuration) et Emplacement de SplitsTree (par exemple C:\Program Files (x86)\SplitsTree\SplitsTree.exe, Ă adapter selon votre configuration).
Voici un corpus possible : discours d'Obama.
Nous allons commencer par crĂŠer un dossier oĂš tous les fichiers crĂŠĂŠs aujourd'hui pour l'utilisation de TreeCloud seront situĂŠs. On choisira un nom de dossier sans espace, par exemple C:\Treecloud\20140118Formation. Vous pouvez y dĂŠposer des fichiers de type texte (extension .txt) qui contiennent les corpus sur lesquels vous souhaitez travailler.
Double-cliquez sur le programme TreeCloud.exe dans le dossier oĂš vous avez dĂŠcompressĂŠ le fichier zip tĂŠlĂŠchargĂŠ ci-dessus.
Copiez-collez un texte quelconque dans le cadre Texte Ă visualiser, ou bien chargez un fichier texte Ă l'aide du bouton Ouvrir un fichier texte.
Cliquez sur Calcule le nuage arborĂŠ avec TreeCloud !. Au bout de quelques secondes, SplitsTree devrait s'ouvrir et le nuage arborĂŠ devrait apparaĂŽtre.
Vous trouverez quelques indications sur les diverses options dans le manuel d'utilisateur, le fichier ManualTreecloud.pdf situÊ dans le même dossier que le programme Treecloud.exe. Essayez de faire varier certains paramètres comme les couleurs, les longueurs d'arête, le nombre de mots du nuage arborÊ, ou encore l'antidictionnaire.
Il est possible de zoomer/dÊzoomer avec les boutons loupe + et -. Il est possible de faire tourner l'arbre avec les boutons flèche gauche et droite
Pour chercher un mot dans le nuage arborĂŠ, on peut utiliser CTRL F ou le bouton des jumelles A.
On peut dĂŠplacer les ĂŠtiquettes en les faisant glisser avec la souris. Pour recolorer les branches de l'arbre, les ĂŠtiquettes, etc., il faut les sĂŠlectionner (CTRL A pour tout sĂŠlectionner) puis utiliser le menu View, Format nodes and edges (CTRL J). Pour modifier les branches, il faut cocher Line Color dans la fenĂŞtre qui s'ouvre. Pour modifier les ĂŠtiquettes, il faut cocher Label Color dans cette fenĂŞtre.
Pour exporter l'image en bonne qualitĂŠ, on peut utiliser le menu File, Export image (CTRL M), puis choisir Save visible region et Format : PDF (par exemple) puis cliquer sur Apply avant d'indiquer le nom de fichier choisi.
Si ce n'est pas dĂŠjĂ fait, installez OpenOffice et Notepad 2 (programme d'installation de Notepad 2 pour x64)
PlutĂ´t que d'utiliser des fenĂŞtres glissantes pour calculer la cooccurrence, il est possible de dĂŠlimiter des blocs de texte qui serviront de fenĂŞtres de cooccurrence, en utilisant un sĂŠparateur. Le sĂŠparateur doit ĂŞtre un mot qui n'apparaĂŽt pas dans le texte, par exemple aaaaa.
Par exemple, considĂŠrons les avis cinĂŠma de la critique cinĂŠma Monique Pantel.
On souhaite que deux mots apparaissent Ă proximitĂŠ dans le nuage arborĂŠ
s'ils apparaissent frĂŠquemment dans une mĂŞme critique de film. On dispose
du fichier OpenOffice monique_pantel.csv :

Nous allons voir comment obtenir un fichier oĂš les critiques sont
sĂŠparĂŠes par aaaaa :
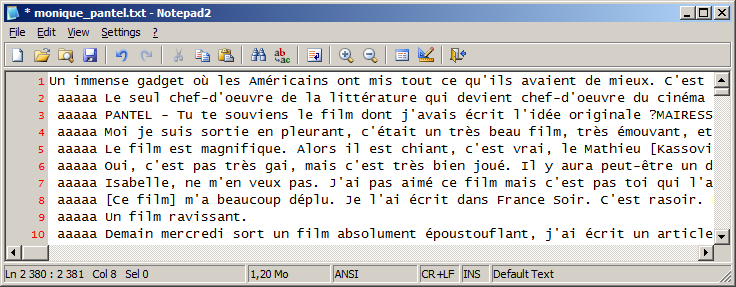
Pour cela, sÊlectionnez toutes les critiques de la colonne D du fichier Open Office, et copiez-les (touches CTRL C). Attention, ne sÊlectionnez pas la colonne entière (il y aurait trop de lignes), mais seulement les cases non vides de la colonne D.
Ouvrez Notepad 2 et collez-les dans Notepad 2. Enregistrez le fichier obtenu sous le nom monique_pantel.txt.
Pour insĂŠrer un aaaaa Ă chaque retour Ă la ligne,
utilisez la fonction
rechercher/remplacer (menu Edit, Replace ou bien CTRL H).
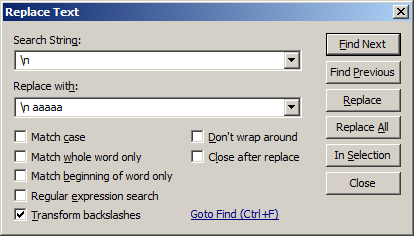
Recopiez les informations de la
fenêtre ci-dessous (attention, il y a un espace après le aaaaa
du Replace with, mais pas après le \n du Search string),
en pensant Ă cocher Transform backslashes
(cela permettra d'interprĂŠter \n comme un retour Ă la ligne)
puis cliquez sur Replace all :
Enregistrez le fichier ainsi modifiĂŠ (CTRL S,
vous obtenez ainsi le fichier monique_pantel.txt)
et chargez-le dans TreeCloud pour obtenir un nuage arborĂŠ des critiques de Monique
Pantel. Pensez Ă indiquer Ă gauche de la fenĂŞtre aaaaa dans le champ SĂŠparateur :

on obtient alors le nuage arborĂŠ suivant, colorĂŠ chronologiquement :

Pour colorer les mots en fonction des notes attribuÊes, on peut rÊorganiser le corpus de telle manière que les critiques avec de mauvaises notes sont au dÊbut, et celles avec de bonnes notes à la fin : on pourra alors utiliser la coloration chronologique qui fera apparaÎtre en rouge les mots liÊs aux critiques les plus nÊgatives
Pour cela, dans OpenOffice, triez la colonne E par ordre croissant (menu DonnĂŠes, Trier, Trier selon : Colonne E, croissant) puis sĂŠlectionnez dans la colonne D les critiques correspondant aux notes non nulles dans la colonne E (car la note 0 indique une absence d'avis). Copiez les cellules sĂŠlectionnĂŠes puis reproduisez les dĂŠmarches ci-dessus pour afficher le nuage arborĂŠ oĂš vous devriez remarquer certains adjectifs nĂŠgatifs en rouge, et des adjectifs positifs en bleu.
Afin d'utiliser Lexico 3 pour construire tous les contextes d'un mot (par exemple le mot formidable), il est prĂŠfĂŠrable de commencer par convertir tous les texte en minuscules, pour traiter ĂŠgalement la forme Formidable avec une majuscule en dĂŠbut de mot. Pour cela, dans Notepad2, sĂŠlectionnez tout le texte (CTRL A) puis allez dans le menu Edit, Convert, Lower case (CTRL U). Enregistrez le fichier obtenu
Ouvrez dans Lexico3 le fichier obtenu
puis crĂŠez-y la concordance de
formidable :

Copiez le contenu de la fenĂŞtre de concordance Lexico3 et dans collez-le dans Notepad2. Reproduisez la procĂŠdure vue ci-dessus pour insĂŠrer des sĂŠparateurs aaaaa Ă chaque retour Ă la ligne.
En dĂŠbut de ligne, il arrive que le premier mot ne soit pas complet.
Nous allons donc supprimer le premier mot de chaque ligne avec
une procĂŠdure de rechercher/remplacer.
Ouvrez dans Notepad2 la
fenĂŞtre rechercher/remplacer (CTRL H).
Dans Search String,
indiquez "aaaaa [^ ]* " (notez l'espace Ă la fin)
et dans Replace with,
indiquez "aaaaa " (lĂ aussi, un espace Ă la fin).
Cochez alors la case Regular
expression search :

Cliquez sur Replace all. Le code du Search string permet de repĂŠrer le mot aaaaa suivi d'un espace suivi d'un mot ne contenant pas d'espace, suivi d'un espace. Ainsi, si l'on remplace cela par aaaaa suivi d'un espace, cela revient Ă supprimer le premier mot.
Supprimez le premier mot de la première ligne du fichier (il n'a pas ÊtÊ supprimÊ car il n'y avait pas de aaaaa).
Vous pouvez dĂŠsormais enregistrer
votre fichier, par exemple sous le nom monique_pantel-formidable.txt,
puis le charger dans TreeCloud pour obtenir la visualisation des contextes
du mot formidable (mots qui apparaissent plus de 4 fois dans ces
contextes) :
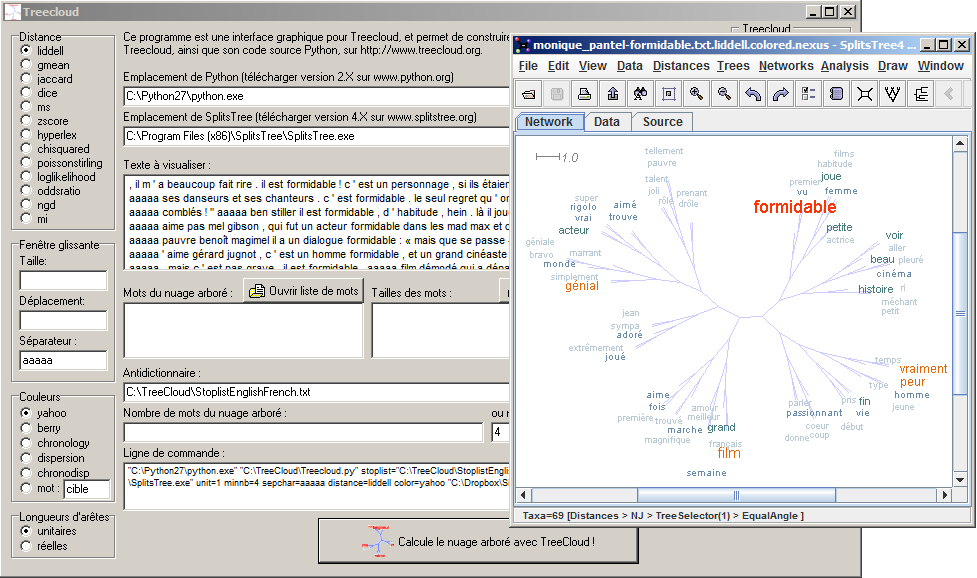
Quand plusieurs mots sont sÊparÊs par le caractère _, TreeCloud les considère comme un seul mot. Par ailleurs, Unitex peut Êtiqueter les mots composÊs d'un texte en les entourant par les balises <CDIC> et </CDIC>. Nous allons donc remplacer les mots entre ces balises par les mêmes mots sÊparÊs par le caractère _.
Pour cela, on utilise encore la fonction rechercher/remplacer de Notepad 2, en cochant Regular expression search, et en remplaçant "<CDIC>([^< ]*) ([^<]*)</CDIC>" par "<CDIC>\1_\2</CDIC>". Il faut rÊpÊter l'opÊration jusqu'à ce qu'aucun remplacement ne soit effectuer.
Puis il faut rÊpÊter toute l'opÊration prÊcÊdente en remplaçant "<CDIC>([^<-]*)-([^<]*)</CDIC>" par "<CDIC>\1_\2</CDIC>", à nouveau jusqu'à ce qu'aucun remplacement ne soit effectuÊ.
Enfin, il faut supprimer les balises <CDIC> et </CDIC> en remplaçant "<CDIC>" par "" et "</CDIC>" par "".
Avant d'enregistrer, il faut convertir le fichier Ă l'encodage acceptĂŠ par TreeCloud : dans le menu File, Encoding, choisir ANSI.


