LDAP - Lightweight Directory Access Protocol
Déploiement
Cette partie du site a pour but de présenter la réalisation et le déploiement d'un annuaire avec LDAP. Les différentes étapes seront détaillées en prenant comme exemple la réalisation d'un annuaire pour la gestion des étudiants et des enseignants à Ingenieurs2000
Inventaire
Lors de la conception d'un annuaire, la première étape consiste à inventorier la liste des données et leurs caractéristiques. C'est une opération similaire au listing des objets du modèle dans le cas d'une base de données. Cette étape va permettre d'organiser ensuite les données lors de la création du schéma. Lors de cette inventaire, il faut également déterminer par quelle source seront obtenues ces données (saisie manuelle s'il n'y a pas d'existant, récupération en provenance d'une application ou d'une base de données). Cette étape est importante car il faut dès le début réflechir à la synchronisation de ces données dans le cas d'une récupération (script bash ou utilisation d'un adaptateur entre l'application et le futur annuaire).
Dans notre exemple, les données ne proviennent pas d'un application externe et nous recensons les informations suivantes :
Filière (l'école est composée de plusieurs filières : IR, EI, MFPI, ..)
Enseignant
Etudiant
Groupe (une filière est composée de plusieurs groupes de TD)
Tuteur ingénieur
Schéma
Une fois les données listés, il faut à présent les organiser afin de les utiliser dans l'arbre de l'annuaire. Le protocole LDAP défini un grand nombre de classes types pour la majorité des cas d'utilisations. Cependant, ces classes peuvent ne pas répondre totalement aux besoins formulés. Il faut ainsi créer ses propres classes en utilisant au maximum l'héritage des classes types de LDAP. C'est une étape critique dans la construction et l'utilisation future de l'annuaire car si elle est possible, la modification du schéma de l'arbre est délicate. Il est souhaitable de prévoir les évolutions dès la création du schéma.
Les classes existantes dans LDAP vont nous servir pour les filières (organizationalUnit) mais pour différencier les étudiants, les enseignants et les tuteurs, nous devons affecter un rôle qui n'est pas prévu dans les classes de bases. Nous créons donc une classe umlvPerson qui hérite d'inetOrgPerson (donc d'un nom, prénom, adresse, téléphone, ...) en lui ajoutant un champ rôle. Un groupe est un organizationalUnit qui possède en plus un umlvPerson identifié comme administrateur de ce groupe.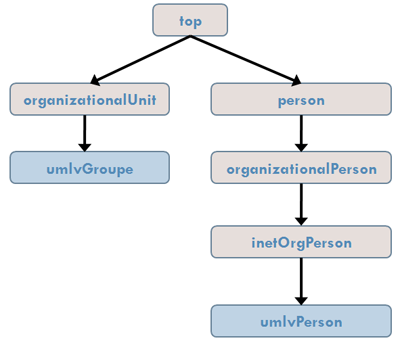
Modèle de nommage
Le schéma créé, l'annuaire en lui même peut maintenant être généré. La création du DIT nécessite l'attribution d'un suffixe. Par convention, le suffixe utilisé est le nom de domaine de l'organisation (tout comme le nommage d'un paquetage en Java). Lors de la création de cet arbre, il est important de prévoir les possibles évolutions futures. En effet, la structure de l'arbre peut être modifiée mais avec précaution afin de ne pas avoir de DN en doublon.
L'arbre DIT ainsi créé est le suivant :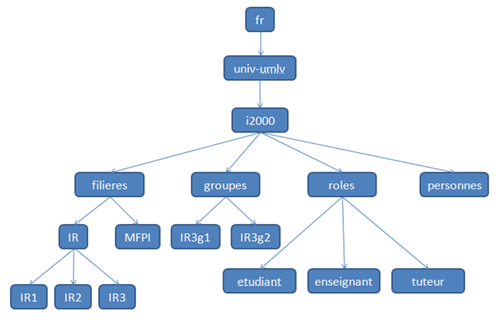
Service
La topologie du service consiste à organiser l'arbre de manière à le partitionner sur plusieurs serveurs. Cela a plusieurs objectifs :
- Répartition de charge et optimisation des accès : Certaines branches peuvent être stockées sur des serveurs disposés près des clients potentiels. Dans notre exemple, la branche de l'arbre IR (pour Informatique et Réseaux) peut être physiquement stockée sur un serveur disposé à l'Université de Marne La Vallée où sont dispensés les cours tandis que la branche EI (pour Electronique et Informatique) peut être stockée physiquement sur un serveur du réseau du CNAM à Saint Denis où se trouve cette filière.
- Répartition de la responsabilité de la maintenance : Répartir l'arbre sur plusieurs serveurs distincts permet également de déléguer la responsabilité de la branche à différents administrateurs par serveurs. Dans le cas de notre exemple, chaque filière peut gérer comme bon lui semble les entrées de sa branche (mécanisme proche de celui de la gestion des noms de domaines).
Réplication
Lors du déploiement d'un annuaire, il est important de reflechir à l'optimisation des accès ainsi qu'à une notion de la sécurité : la disponibilité
La réplication permet d'assurer :
- Une répartition de charge dans le cas oû plusieurs serveurs possèdent une copie d'une même branche
- Une haute disponibilité afin de prévoir l'arrêt soudain d'un serveur sans arrêter le service
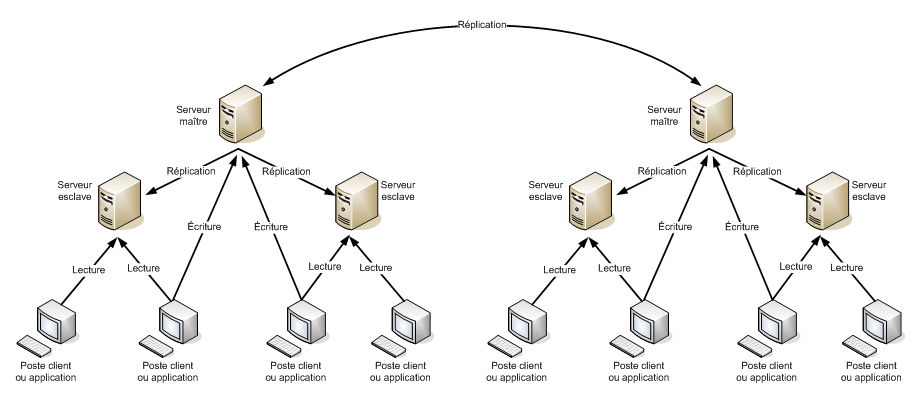
L'architecture ci-dessous permet, par exemple, d'effectuer les requêtes nombreuses de lecture sur des serveurs esclaves tandis que les requêtes d'écritures (plus rares) sont redirigées (via le mécanisme de referral) vers l'unique serveur maître qui a la responsabilité de répliquer cette écriture sur ses serveurs esclaves. Ainsi les requêtes de lecture sont assurées par plusieurs serveurs. Pour obtenir une haute disponibilité, il est possible de dupliquer le serveur maître et de les répliquer entre eux lors d'une écriture.
Sécurité
Une des notions importantes de sécurité ici est l'accès à des données / opérations non autorisées. Bien que la version 3 du protocole LDAP n'inclue pas la notion d'habilitation, la grande majorité des implémentations des serveurs dispose d'ACL (Access Control List) par le biais des extensions prévus par LDAPv3.
Il convient donc d'étudier pour chaques données de l'annuaire (chaque attribut de chaque classe) son niveau d'accessibilité
Dans notre exemple, nous souhaitons que le mot de passe d'un utilisateur ne soit visible et modifiable que par lui même et par l'administrateur. Nous souhaitons également que le salaire d'une personne ne soit visible que par lui même et par l'administrateur mais modifiable que par l'administrateur. Dans le cas du serveur OpenLDAP, ces règles se traduisent par les directives suivantes dans le fichier de configuration : (l'administrateur ayant tous les droits)
access to attr=userPassword by self write by * none
access to attr=salary by self read by * none