Calcul générique sur GPU
PyOpenCL
Environnement Windows 7/8 (32 ou 64 bits)
Avant de commencer, voici un récapitulatif simple et précis pour ne par perdre des heures ŕ chercher quels modules installer.
1. Installer Python 2.7.6
2. Installer le module PyOpenCL MKL (32 ou 64 bits) pour python 2.7
3. Installer le module Numpy (32 ou 64 bits) pour python 2.7
4. Ajouter la variable d'environnement PYOPENCL_COMPILER_OUTPUT avec 1 comme valeur
5. Installer le module Pytools
6. Installer le package SetupTools
Premier programme
Une fois la préparation de l'environnement, on peut facilement tester avec un script basique.
import pyopencl as cl import numpy import numpy.linalg as la a = numpy.array(range(10), dtype=numpy.float32) b = numpy.array(range(10), dtype=numpy.float32) ctx = cl.create_some_context() queue = cl.CommandQueue(ctx) mf = cl.mem_flags a_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a) b_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b) dest_buf = cl.Buffer(ctx, mf.WRITE_ONLY, b.nbytes) prg = cl.Program(ctx, """ __kernel void sum(__global const float *a, __global const float *b, __global float *c){ int gid = get_global_id(0); c[gid] = a[gid] + b[gid]; } """).build() prg.sum(queue, a.shape, None, a_buf, b_buf, dest_buf) a_plus_b = numpy.empty_like(a) cl.enqueue_copy(queue, a_plus_b, dest_buf) print "a",a print "b",b print "a_plus_b",a_plus_b
Ce script fait la somme de deux matrices que l'on peut voir comme un tableau ŕ une dimension. Aprčs exécution nous obtenons la sortie suivante :
a [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
b [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
a_plus_b [ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18.]
Quelques explications : Tout d'abord nous devons préparer les données que nous voulons utiliser grâce au module NumPy.
a = numpy.array(range(10), dtype=numpy.float32) b = numpy.array(range(10), dtype=numpy.float32)
Ici, le but est d'initialiser deux tableaux numpy avec des valeurs de 0 ŕ 9. Les tableaux sont remplis avec des données réelles.
Ensuite on créer le contexte d'OpenCL ainsi que la file d'attente de commandes.
ctx = cl.create_some_context() queue = cl.CommandQueue(ctx)
Ici, nous créons deux tampons OpenCL oů nous passons les données ŕ copier (respectivement a et b). Nous créons aussi un tampon "destination" que nous allons utiliser pour stocker les résultats de notre calcul.
mf = cl.mem_flags a_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a) b_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b) dest_buf = cl.Buffer(ctx, mf.WRITE_ONLY, b.nbytes)
Le kernel est fait par chacun des workers en OpenCL. Dans un GPU ces workers sont appelés threads, ils sont exécutés par lots appelés workergroup. Donc, nous voulons faire ce qui serait normalement une boucle parallčle, nous avons donc besoin de le diviser en petit morceaux de travail qui peut ętre calculer simultanément. Dans ce cas, il est assez simple, nous affectons simplement chaque élément des tableaux ŕ une partie des données, et le travail est réparti sur chacun des éléments du tableau de sortie. OpenCL alloue alors ce peu de travail (addition de deux nombres) ŕ chaque worker. La façon d'accéder et de stocker les bons éléments de données se fait ŕ l'aide de l'index du worker (get_global_id) comme les index pour accéder aux données dans un tableau.
prg = cl.Program(ctx, """ __kernel void sum(__global const float *a, __global const float *b, __global float *c){ int gid = get_global_id(0); c[gid] = a[gid] + b[gid]; } """).build()
On appel la méthode pour que le programme exécute le kernel (sum), cela est fait comme n'importe quelle autre fonction, en passant dans notre file d'attente de commandes, les worksizes globaux et locaux. Nous passons ensuite dans les trois paramčtres ŕ notre noyau, les trois tampons OpenCL que nous avons créé.
prg.sum(queue, a.shape, None, a_buf, b_buf, dest_buf)
Nous lisons les données de la mémoire tampon de destination calculées par OpenCL. Puis on copie les résultats dans le tableau destiation pour ensuite pouvoir afficher les résultats.
a_plus_b = numpy.empty_like(a) cl.enqueue_copy(queue, a_plus_b, dest_buf)
Performance
Voici les temps d'exécution du kernel mesurés sur un ordinateur portable Leonovo T420 Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz avec un GPU intégré Intel(R) HD Graphics Family.
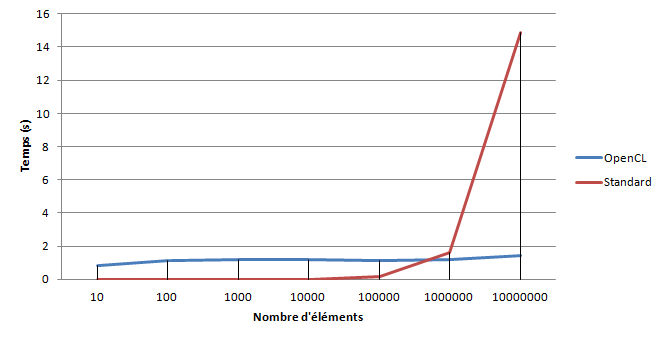
On peut clairement constater la parallélisation mise en place par opencl ŕ partir d'un tableau de 1 000 000 d'éléments.