Le framework Apache Hadoop
MapReduce
Qu'est ce que MapReduce ?
La notion de MapReduce, issue à l'origine de la programmation fonctionnelle, peut désigner plusieurs choses :
- Un modèle de programmation pour faire du calcul distribué
- Un framework, développé par Google dans le cadre de son architecture de calcul interne
- Une implémentation Hadoop permettant de faire du calcul distribué
Ici, nous allons nous concentrer sur le fonctionnement de ce modèle de programmation, implémenté dans le cadre d'Hadoop.
Fonctionnement de MapReduce
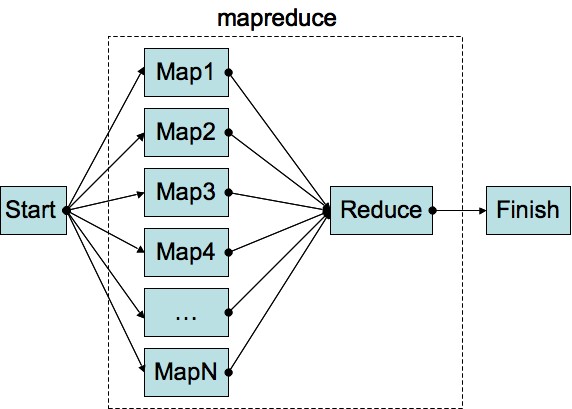
Fonctionnement de l'exécution d'une tâche MapReduce
Une tâche MapReduce a pour objectif de produire des résultats en sortie à partir d'une source de données en entrée et ce, de manière distribuée.
Pour cela, deux fonctions sont exécutées afin d'effectuer un traitement sur les données :
- La fonction map, qui va traiter l'ensemble des données par décomposition en sous-problèmes. Dans le cadre d'Hadoop, cela se traduit par plusieurs exécutions de la fonction map, sur les machines esclaves hébergeant les données. Cette fonction produira une série de paires clés-valeurs.
- Une étape intermédiaire, combine, gérée directement par hadoop, aura pour rôle de trier et de regrouper les paires avec des clés identiques.
- Une fois ces données traitées par les fonctions map et combine, la fonction reduce traitera les résultats intermédiaires des fonctions map exécutées afin de produire une solution unique au problème de la tâche.
Dans la cadre de l'architecture que nous avons vu précédemment, le JobTracker va répartir les fonctions map à exécuter sur les machines esclaves (TaskTracker) et exécuter la fonction reduce qui permettra de produire le résultat de la tâche.
Hadoop fournit une abstraction de l'exécution de tâches distribuées au travers de son système de fichiers HDFS, que nous allons voir dans la partie suivante.