jOpenDocument
Démonstration
Présentation du contexte
J'ai choisi pour ma démonstration de présenter comment pourrais me servir la librairie jOpenDocument dans le cadre d'un projet informatique.
Le but du projet est de migrer un répertoire partagé de type NetAPP(Windows) vers un système documentaire de GED (Gestion Electronique de document). Les documents dans ce SI possèdent beaucoup plus d'informations telles qu'un Type, une référence ou un classement. Ce qui leur permettent d'être indexés dans une recherche et d'être retrouvés par n'importe qui n'importe où.
Voici le schéma du principe :

Ce qu'il faut comprendre de ce schéma est assez simple, un utilisateur scanne un répertoire sur les serveurs par l'intermédiare de l'outil de migration.
Ensuite l'outil de migration montre à l'utilisateur l'arborescence des fichiers et lui permet de renseigner des méta-données pour les fichiers à migrer(Titre, Sécurité...).
Une fois toutes les données enregistrées, l'utilisateur peut envoyer en migration ses fichiers. Toutes ces informations se retrouvent ensuite dans un fichier Pivot.
Ce fichier pivot sert en effet de pivot entre notre outil et l'outil de la DSI qui fait effectivement la migration vers le système de GED car nous n'avons pas les accès.
Le problème est que l'utilisateur doit remplir pour chaque fichier analysé les méta-données correspondantes, on se doute bien que s'il y a 10000 fichiers, la migration est impossible. Nous préconisons donc de le faire sur de petits repertoires ce qui rend la migration beaucoup plus longue qu'escontée.
Mais, maintenant imaginons qu'on puisse récupérer des informations directement dans le document et construire le fichier pivot sans l'action de l'utilisateur.
Là où nous avons de la chance, c'est que dans mon entreprise, tous les fichiers possèdent un template, et le premièr onglet de chaque fichier est un Index qui possède les informations dont on a besoin. Voici un screen de cet index :
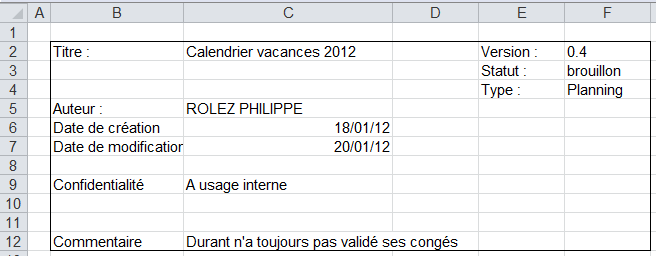
On remarque que si on récupère les informations des cellules « titre »(C:2), « la confidentialité »(C:9), « le commentaire »(C:12), « la version »(F:2), « le statut »(F:3) et « le type »(F:4), on pourrait faire ce qu'on veut.
J'ai donc réalisé un exécutable permettant de construire le fichier pivot sans aucune intervention de l'utilisateur.
À télécharger ici. Il faut cependant installer la version 1.7 du jre JAVA (Les fonctionnalités d'extraction de données sur les serveurs partagés comme les ACLs ... ne sont disponibles que depuis JDK 7).
La marche à suivre est la suivante : appuyez sur le bouton au démarrage, sélectionnez un répertoire à analyser. Une fois le chargement terminé, le fichier pivot s'est créé sur le bureau.
Note : pour que l'exécutable puisse analyser vos fichiers, il faut au préalable changer dans LibreOffice le format OpenDocument utilisé et mettre OpenDocument 1.1. (Outils->Options->Chargement/enregistrement->Général->Version du format ODF)
Allez y jeter un coup d'oeil.