Introduction au Reverse Engineering

Généralités
Architecture type
Pour identifier clairement le domaine associé au Reverse Engineering, voici un schéma "d'architecture" représentant le cycle normal de la création d'une application, ainsi que le cycle associé à son "reversing":

On retrouve ici:
Le cycle classique d'Engineering (du code source vers le comportement, ou de la gauche vers la droite) :
- On peut soit partir du code source, que l'on va compiler pour générer un fichier binaire exécutable,
- Soit partir du code assembleur que l'on va assembler pour obtenir également un fichier binaire exécutable.
C'est cet exécutable qui va définir un comportement, spécifique à chaque programme généré (binaire).
Le cycle Reverse d'Engineering (du comportement vers le code source, ou de la droite vers la gauche) :
- On peut démarrer l'analyse à partir du binaire, que l'on va décompiler pour obtenir un code source similaire à celui d'origine. Les décompilateurs sont capables de générer un code source possédant un contenu similaire au code d'origine, mais dont toute la syntaxe a été regénérée (ces informations disparaissent lors de la compilation et ne peuvent donc pas être retrouvées à partir du binaire).
- On peut également démarrer l'analyse à partir du binaire, mais que l'on va chercher à désassembler pour obtenir le code assembleur (Langage très bas niveau, proche de la machine). Cela permet d'observer les spécificités du code exécutable produit pour un certain type de processeur, et de réaliser une analyse beaucoup plus poussée du binaire, mais aussi plus difficile.
C'est dans ce cadre que l'on peut définir les contextes d'analyse :
- Lorsque l'on a uniquement accès au comportement du programme (entrées/sorties) sans avoir accès à l'éxécutable, on parle d'analyse en boîte noire.
- Par contre, lorsque l'on dispose d'un accès au binaire ou à l'exécutable du programme, on parle d'analyse en boîte blanche.


Winter is coming; Game of Thrones, Eddard ’Ned’ Stark
Contexte d'analyse
Une analyse en boîte blanche ou en boîte noire ne représente pas uniquement les seules contextes d'analyse pouvant subvenir pendant le reversing.
En effet, on retrouve également la notion de contexte d'analyse statique et dynamique.
Pour bien comprendre ces notions, nous allons définir les contextes d'analyses en boîte noire et blanche, ainsi que les notions sous-jacentes à ces situations.
Voici un schéma type d'une analyse en contexte boîte noire :
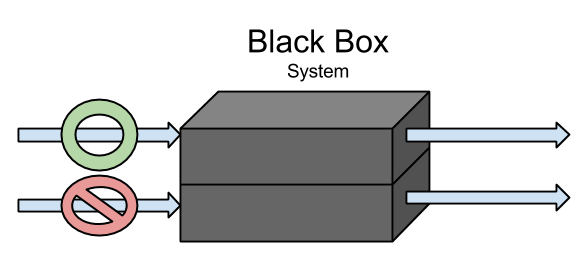
Une analyse en boîte noire signifie que l'on n'a pas d'accès au binaire ou programme que l'on souhaite étudier. Il faut donc explorer, approfondir le comportement de ce dernier durant son exécution.
Une analyse dépendant d'une exécution du produit représente une analyse dynamique. Dans le cadre d'une boîte noire, une analyse statique n'a aucun sens. En effet, cela signifierait analyser un produit sans y avoir accès, et en dehors de toute exécution, ce qui n'est de facto pas possible.
On peut décomposer une analyse en boîte noire dynamique selon deux cas :
- Analyse passive: L'étude du programme se fait sans aucune interaction avec les entrées/sorties. On regarde ici uniquement les entrées et sorties du programme, sans pouvoir interférer avec,
- Analyse active: L'étude du programme se fait en intéragissant avec les entrées/sorties. On peut ainsi choisir les données que l'on donnera en entrée, pour ainsi observer le résultat sur les sorties du programme.
Voici un schéma type d'une analyse en contexte boîte blanche :
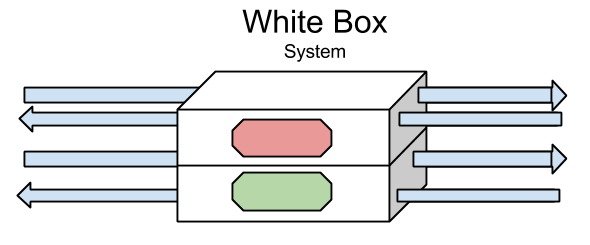
Une analyse en boîte blanche signifie que l'on dispose d'un accès au binaire ou programme que l'on souhaite étudier. On peut donc explorer et approfondir le comportement de ce dernier durant son exécution.
Une analyse en boîte blanche peut se décomposer selon deux cas :
- Analyse dynamique: Comme décrit précédemment, une analyse dynamique consiste à étudier le fonctionnement d'un programme durant son exécution. On peut ainsi parler d'analyse dynamique active ou passive de la même manière qu'avec une analyse en boîte noire.
- Analyse statique: Une analyse statique consiste à analyser le programme indépendamment de toute exécution. On va ainsi réaliser un désassemblage du programme, ou le décompiler pour ainsi étudier le code source généré. Il existe deux grandes familles dans ce domaine : l'anayse syntaxique, qui se base sur la forme du programme, et l'analyse sémantique, qui recherche l'ensemble des comportements possibles du programme.
Niveaux d'abstractions
Un autre concept spécifique au Reverse Engineering est le niveau d'abstraction que l'on peut prendre durant le cadre d'une analyse.
En effet, une analyse peut s'effectuer à différents niveaux, dont voici les principaux à retenir :
- Applicatif : Dans ce niveau, on recherche à comprendre les concepts et le domaine d'application du produit étudié : prologiciel de gestion, protocole d'échanges de données, etc...
- Structure et données : On recherche ici à comprendre les structures et types de données associées au produit : Architecture et design pattern utilisés, type de données manipulées, etc...
Implémentation : A ce niveau, On étudie la façon dont le produit a été implémenté :
- Table des symboles utilisés (table contenant les informations comme le type, la portée, la visibilité, etc... créé lors d'une compilation entre l'analyse lexicale et syntaxique),
- les chaînes de caractères utilisés, ce qui permet de retrouver les appels à tel ou tel type de librairies, ce qui améliore d'autant plus la compréhension du programme (manipulation d'entrées/sorties, mathématiques, ....)
Il faut bien entendu connaître le domaine applicatif avant d'étudier l'implémentation du logiciel analysé, pour ainsi avoir une vue globale avant de redescendre au niveau de la structure et de l'implémentation.