LMAX-Architecture
Le pattern Disruptor
Introduction au Disruptor
La conception du pattern Disruptor a émergé à travers une séparation rigoureuse des préoccupations que LMAX a vu comme étant confondu dans les files d'attente. Cette approche a été combinée avec un accent sur la garantie que toutes les données doivent être détenue par un seul thread pour l'accès en écriture, ce qui élimine la contention en écriture. Ce design est devenu connu sous le nom "Disruptor"(perturbateur en Francais).
Il a été ainsi nommé parce qu'il avait des éléments de similitude pour traiter des graphiques de dépendances à la notion de "Phasers" dans Java 7, introduit pour soutenir Fork-Join.
Le Disruptor crée par LMAX est conçu pour répondre à tous les problèmes des files d'attente et ainsi tenter de maximiser l'efficacité de l'allocation de mémoire, et d'exploiter d'une manière cache-friendly de sorte qu'il se produira de façon optimale sur du matériel moderne. Au cœur du mécanisme du Disruptor se trouve une structure pré-alloué bornée des données sous la forme d'un tampon en anneau(voir Ring Buffer). Les données sont ajoutées au tampon en anneau par le biais d'un ou de plusieurs producteurs et traitées par un ou plusieurs consommateurs.
Allocation de mémoire
Toute la mémoire pour le tampon en anneau est pré-alloué au démarrage. Un tampon en anneau peut stocker un tableau de pointeurs vers les entrées ou un tableau de structures représentant les entrées. Les limitations du langage Java signifie que les entrées sont associées au ring buffer comme des pointeurs vers des objets. Chacune de ces entrées n'est généralement pas les données étant lui-même passé, mais un conteneur pour lui. Cette pré-allocation élimine les problèmes des langages qui utilise un garbage collector, car les entrées seront ré- utilisé et vivent pendant toute la durée de l'instance Disruptor. La mémoire pour ces entrées est alloué dans en même temps et il est fort probable qu'il sera aménagé de manière contiguë dans la mémoire principale et ainsi permettre de soutenir les grands saut de cache. Il s'agit d'une proposition par John Rose d'introduire les types de valeur "pour le langage Java qui permettrait des tableaux de tuples, comme d'autres langages telles que le C, et ainsi de veiller à ce que la mémoire soit allouée de façon contiguë et éviter l'indirection de pointeur. Le GC peut être problématique lors de l'élaboration des systèmes à faible latence dans un environnement d'exécution géré comme en Java. Plus il y a de mémoire qui est allouée plus il y en a à garbage collecter. Les éboueurs travaillent de leurs mieux lorsque les objets sont soit de très courte durée ou effectivement immortel. La pré-affectation des entrées dans l'anneau tampon signifie qu'il est immortel dans la mesure où le garbage collector est concerné et représente donc peu de charge. Cela a deux conséquences: d'abord, les objets doivent être copiés entre les générations qui provoque la gigue de latence, d'autre part, ces objets doivent être collectées à partir de l'ancienne génération qui est typiquement une opération plus coûteuse et augmente la probabilité de pauses qui se produisent lorsque la mémoire fragmentant l'espace nécessite un compactage. Dans des tas de mémoire ce qui peut causer de grandes pauses de plusieurs secondes par Go dans la durée.
Outre les préoccupations
Nous avons vu les préoccupations suivantes comme étant confondu dans toutes les implémentations des files d'attente, dans la mesure où cette collection de comportements distinct ont tendance à définir les interfaces que les files d'attente mettent en œuvre:
- Entreposage des biens échangés
- Coordination des producteurs revendiquant la séquence suivante pour l'échange
- Coordination des consommateurs étant avisé qu'un nouvel élément est disponible
Lors de la conception d'un échange financier dans un langage qui utilise la Garbage Collection, la sur-allocation de mémoire peut être problématique. Donc, comme nous l'avons décrit plus tôt, les listes chainées ne sont pas une bonne approche. Le GC est réduits au minimum si le stockage dans son intégralité pour l'échange de données entre les étages de traitement peut être pré-alloués. En outre, si cette allocation peut être réalisée dans un bloc uniforme, la traversée de ces données sera faite d'une manière qui utilise les stratégies de mise en cache utilisée par les processeurs modernes. Une structure de données qui répond à cette exigence est un tableau avec toutes les cases pré-remplis. Lors de la création de la mémoire tampon anneau du Disruptor, il utilise le modèle de fabrique abstraite pour pré-allouer les entrées. Quand une entrée est demandée, un producteur peut copier ses données dans la structure pré-alloué. Sur la plupart des processeurs il ya un coût très élevé pour le calcul du numéro de séquence, qui détermine la case dans l'anneau. Ce coût peut être considérablement réduit en faisant de la taille de l'anneau une puissance de 2. Un masque de bits peut être utilisé pour effectuer l'opération de reste efficacement. Comme nous l'avons décrit précédemment les files d'attente délimitées souffrent de conflits à la tête et la queue de la file d'attente. Les données du tampon d'anneau et la structure sont libre à partir de ces primitives de contention et de la concurrence parce que ces préoccupations ont été gérées en dehors dans les barrières producteurs et consommateurs à travers lesquelles le tampon de l'anneau doit être consulté. La logique de ces obstacles est décrite ci-dessous.
Dans la plupart des usages ordinaires du Disruptor il y a habituellement un seul producteur. Les producteurs typiques sont des lecteurs de fichiers ou de réseau. Dans les cas où il ya un seul producteur il n'y a aucun conflit sur la séquence / attribution d'entrée. Dans les usages les plus inhabituels où il y a plusieurs producteurs, les producteurs feront la course en demandant la prochaine entrée dans le ring buffer. La contention sur les demandes de la prochaine entrée disponibles peuvent être gérés par une simple opération CAS. Une fois qu'un producteur a copié les données pertinentes à l'entrée selon elle peut le rendre public aux consommateurs par la publication du numéro de séquence. Cela peut être fait sans le TAS par une simple rotation occupé jusqu'à ce que les autres producteurs ont atteint cette séquence dans leur engagement propre. Alors, ce producteur peut faire avancer le curseur signifiant l'entrée suivante disponible pour la consommation. Les producteurs peuvent éviter envelopper le noyau par le suivi de la séquence des consommateurs comme une opération de lecture simple, avant qu'ils ne écrire à la mémoire tampon en anneau. Les consommateurs attendent qu'une séquence devienne disponible dans la mémoire tampon en anneau avant de lire l'entrée. Diverses stratégies peuvent être utilisée en attendant. Si les ressources d'unité centrale sont précieuces ils peuvent attendre sur une variable de condition au sein d'un verrou qui obtient un signalement par les producteurs. C'est évidemment un point de discorde et ne doit être utilisé lorsque la ressource CPU est plus importante que la latence ou le débit. Les consommateurs peuvent également vérifier le curseur qui représente le moment où la séquence devient disponible dans la mémoire tampon en anneau.
Séquençage
Le séquençage est le concept de base de la façon dont la concurrence est gérée dans le Disruptor. Les producteurs réclament le slot suivant dans la séquence ou revendiquent une entrée dans le ring buffer. Cette séquence de la case disponible suivante peut être un simple compteur dans le cas d'un seul producteur ou un compteur mis à jour en utilisant les opérations atomiques CAS dans le cas de plusieurs producteurs. Une fois qu'une valeur de séquence est revendiquée, cette entrée dans le tampon circulaire est maintenant disponible pour être écrite par le producteur prétendant. Lorsque le producteur a terminé la mise à jourde l'entrée il peut valider les modifications en mettant à jour un compteur séparé qui représente le curseur sur le tampon en anneau pour la dernière entrée à la disposition des consommateurs. Le curseur tampon en anneau peut être lu et écrit dans un spin occupée par le producteurs en utilisant une barrière de mémoire, sans nécessiter une opération CAS comme ci-dessous.
expectedSequence long = claimedSequence - 1;
while (curseur! expectedSequence =)
{
//Rotation occupés
}
cursor = claimedSequence;
Les consommateurs patientent pour une séquence donnée à l'aide d'une barrière de mémoire pour lire le curseur. Une fois que le curseur a été mis à jour les barrières de mémoire s'assurent que les modifications apportées aux entrées de la mémoire tampon en anneau sont visibles pour les consommateurs qui ont attendus sur le curseur. Les consommateurs contiennent chacun leur propre séquence qu'ils mettent à jour comme ils traitent des entrées depuis la mémoire tampon en anneau. Ces séquences de consommation permettent aux producteurs de suivre les consommateurs et ainsi éviter que la bague s'enroule. Les séquences de consommation également permettent aux consommateurs de coordonner les travaux sur la même entrée d'une manière ordonnée. Dans le cas d'un seul producteur, et quelle que soit la complexité du graphe des consommateurs, il n'y a pas de verrous ou de CAS mis en place. La coordination de la concurrence peut être réalisé avec des barrières de mémoire seulement sur la séquence discuté.
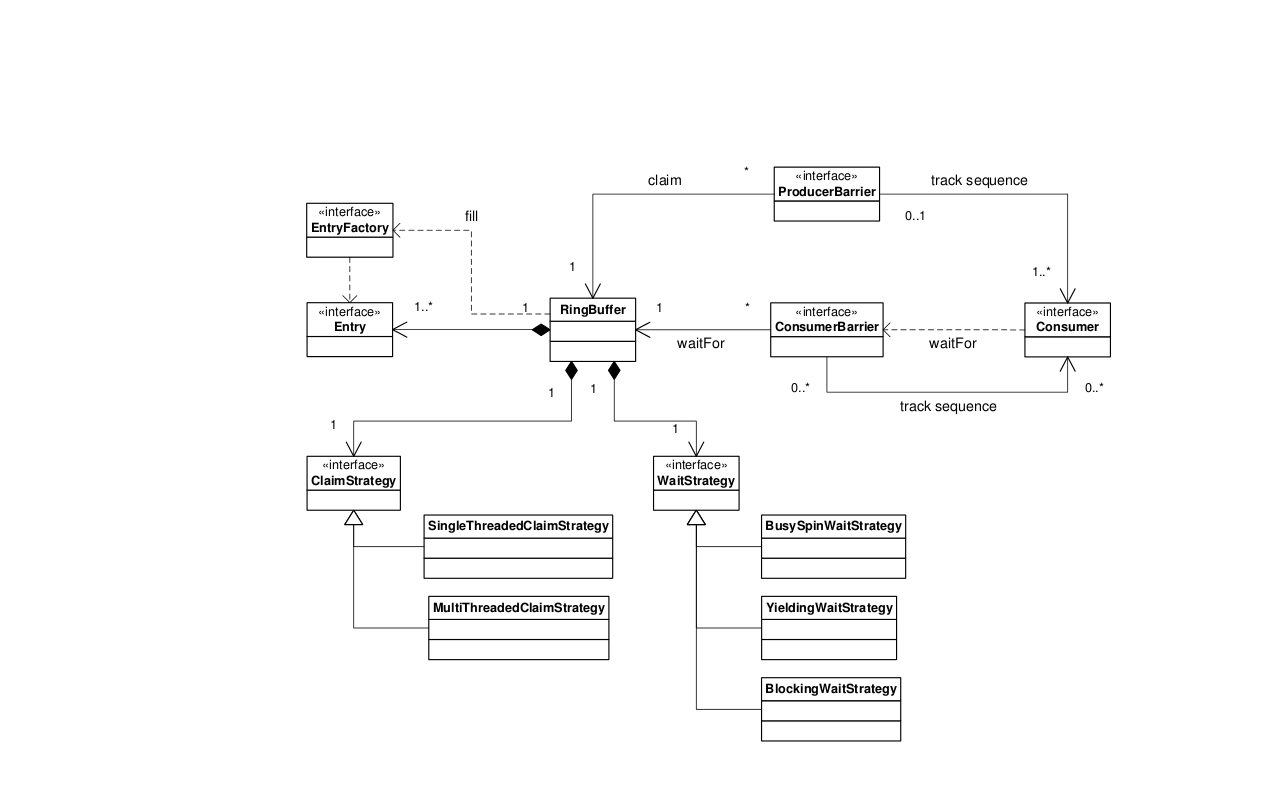
Diagramme de classes Disruptor
Les relations de base dans le cadre du Disruptor sont représentés dans le diagramme de classe ci-dessous. Ce schéma laisse de côté les classes de proximité qui peuvent être utilisés pour simplifier le modèle de programmation. Les producteurs affirment entrées dans l'ordre via la ProducerBarrier, ils écrivent leurs changements dans la case selon l'entrée, puis s'engagent à ce que l'entrée de retour via le ProducerBarrier les rendant disponibles pour la consommation. En tant que consommateur tout ce qu'on doit faire est de fournir une mise en œuvre BatchHandler qui reçoit les rappels quand une nouvelle entrée est disponibles. Ce modèle de programmation qui en résulte est événementiel en fonction des similitudes avec le modèle de l'acteur.
La séparation des préoccupations normalement associés dans une file d'attente des implémentations permet une conception plus souple. Il existe au cœur du modèle Disruptor, le ring buffer assurant le stockage d'échange de données sans contention. La simultanéité est séparées pour que les producteurs et les consommateurs interagissent avec le tampon en anneau. Le ProducerBarrier gère toutes les préoccupations de concurrence liés à la case demandée de la mémoire tampon en anneau. Le ConsumerBarrier avise les consommateurs lorsque de nouvelles entrées sont disponibles, et les consommateurs peuvent être construits dans un graphe de dépendances représentant plusieurs étapes dans un pipeline de traitement.