CUDA et Programmation Générale sur GPU
Optimisations
Axes
La programmation sur GPU avec CUDA présente une approche intéréssante pour l'exécution d'applications distribuées. Cependant, un certain nombre de points sont à surveiller pour maximiser le rendement d'une telle solution, parmi lesquels :
- Maximiser l'occupation du GPU (occupation des registres, répartition de la mémoire partagée)
- Optimiser les accès mémoires (coût et bande passante)
- Minimiser l'utilisation d'instructions conditionnelles dans un kernel (alourdit la gestion interne)
- Optimiser le code pour minimiser l'utilisation d'instruction coûteuses
Bande Passante
Les transferts mémoire entre l'hôte (host) et le périphérique (device) s'effectuent sur un bus PCI Express, qui dispose d'une bande passante limitée (théorique de 8Go/s sur un bus PCIe 2.0 16x). Il faut toutefois garder en mémoire que ce bus peut également servir aux échanges de l'OS si la carte est utilisée en même temps comme carte vidéo. En témoigne ce test de bande passante CUDA mesurées :
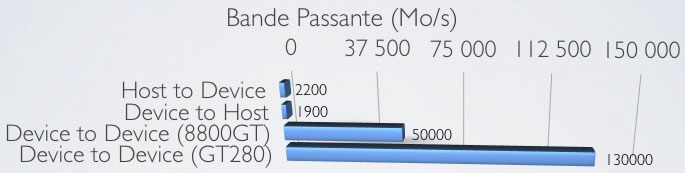
Ces limites sont à prendre en compte dans le développement, car elles peuvent vite devenir des goulot d'étranglement au système.
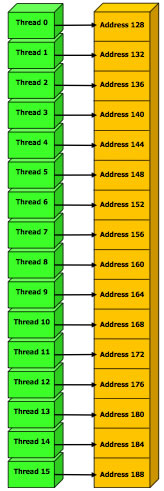
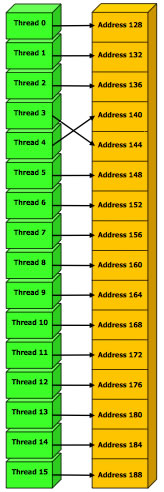
Regrouppement d'accès mémoire
Certains accés à la mémoire globale (très coûteux) peuvent être regrouppés pour minimiser l'impact de performances. Il faut pour cela qu'au moins tous les threads d'un demi-warp accèdent à des cases mémoires consécutives.
Le détail des contraîntes à respecter pour que le GPU optimise les accès mémoire sont disponibles sur le CUDA Programming Guide de nVIDIA.
1 Accès mémoire |
16 Accès mémoire |
Le coût des instructions
Le coût de quelques instructions :
| Instruction | Coût |
|---|---|
| float (32b): add, mul, mad int (32b): add, mul(24b) opérations bit-à-bit, min, max, cmp accès en mémoire partagée |
4 cycles |
| int (32b): mul | 16 cycles |
| float (32b): div (moins précis) | 20 cycles |
| float (32b): div int (32b): div sin(x), cos(x), exp(x) |
36 cycles |
| Accès en mémoire globale | 400 à 600 cycles |
Les Outils
nVidia propose une un outil sous forme de feuille excel qui calcule le taux d'occupation des warps du GPU en fonction des différents paramètres de l'application (génération du GPU cible, nombre de registres utilisés par thread, nombre de threads par blocs, mémoire partagée par bloc).
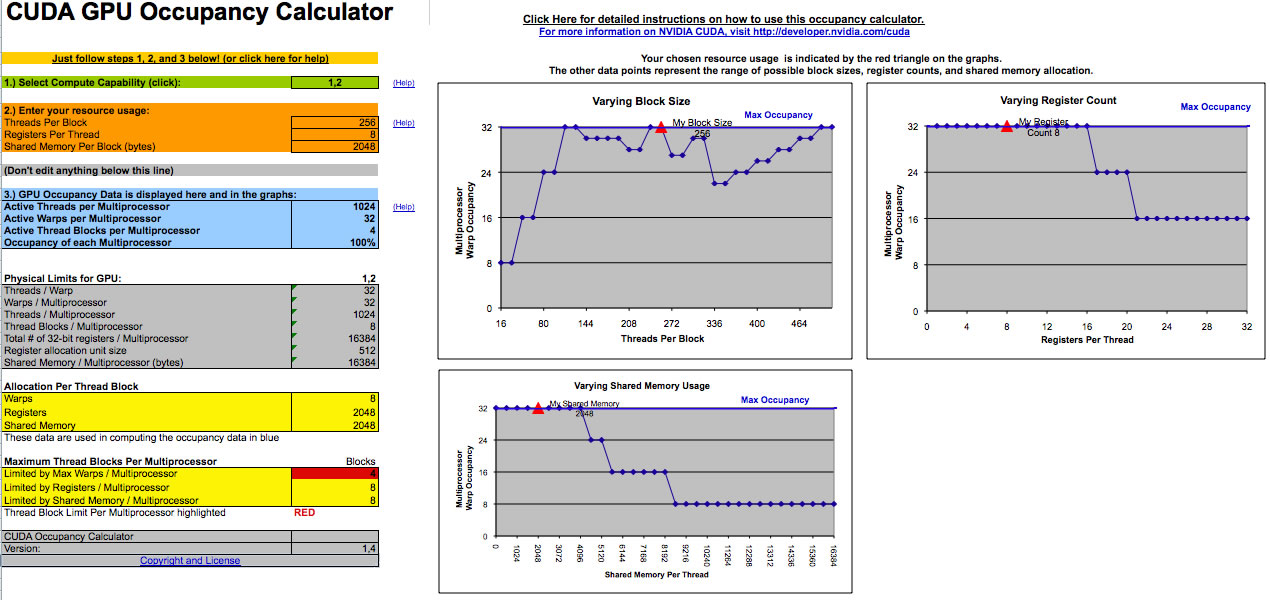
Les informations à remplir sur cette outil peuvent être obtenus en ajoutant l'option de compilation "--ptxas-options=-v" à nvcc.