Apache Solr
Configuration
Prsentation
Solr est très configurable. Globalement deux fichiers XML contenus dans "example/solr/conf" sont paramétrables :
- solrconfig.xml
- schema.xml
Mais nous nous intéresserons pas à cette partie dans ce site web car la configuration de base est suffisante. Pour plus d'informations, consulter la page du wiki dédié à ce sujet : http://wiki.apache.org/solr/SolrConfigXml.
Schema
Le fichier schema.xml est le fichier permettant de décrire le format des documents manipulés par l'index
La page du Wiki qui traite du schema est : http://wiki.apache.org/solr/SchemaXml.
Ce fichier va en fait regrouper les types des champs des documents indexés, ainsi que leur comportements :
-
Des types primitifs prédéfinis sont disponibles : int, float, string, date, boolean, etc.
D'autre part, des types spécifiques à Solr sont à disposition, comme par exemple le type text.
-
Le comportement des types est paramétrable selon 2 modes : à l'indexation et lors de la recherche.
Il s'agit de définir un Tokenizer décrivant la façon dont sont découpés les mots (selon la ponctuation, les espaces, etc.). Il est par ailleurs possible d'appliquer des filtres. Il en existe plusieurs comme par exemple le filtre de sensibilité à la casse ou encore le filtre de stemming dont le but est de réduire tous les mots à leur racine.
C'est dans ce fichier qu'est spécifié le champ représentant l'identifiant unique d'un document, ainsi que l'ensemble des champs dans lesquels par défaut la recherche est effectée.
Lorsque dans une requête, on ne préfixe pas la valeur recherchée par le champ, la recherche s'effectuera dans ce ou ces champs spécifiés.
Exemple : définition du type text
Voici ci-dessous un extrait du fichier schema.xml, correspondant à la définition du type Text. Ainsi un champ qui sera défini avec le type Text aura les propriétés suivantes :
<fieldType name="text" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/> </analyzer> </fieldType>
On retrouve bien dans cette définition du type Text, les deux modes d'analyse différents : à l'indexation (index) et à la requête (query).
Ici le tokenizer utilisé coupe les mots selon les espaces (WhitespaceTokenizer).
Il est important que le Tokenizer soit le même à l'indexation et lors d'une requête, sinon ce ne sera pas possible
de rechercher dans les documents que l'on a indexés.
Un filtre StopFilter est appliqué dans le but de supprimer toutes les articles (le, la, les, un, etc.). Le fichier
"stopwords.txt" permet de regrouper tous ces mots-clés.
On constate qu'un second filtre (Synonyms) est appliqué uniquement pour la partie requête. En effet, ce filtre
permet de vérifier si des mots comportent des synonymes, pour pouvoir matcher un plus grand nombre de
termes. Le fichier "synonyms.txt" contient l'ensemble des termes associés à leurs synonymes.
Voici un exemple de contenu des deux fichiers texte évoqués ci-dessus :
stopwords.txt :
|
#Standard english #stop words an and as at be but by for if in … |
synonyms.txt :
|
# Some synonym groups GB,gib,gigabyte,gigabytes MB,mib,megabyte,megabytes Television, Televisions, TV, TVs spider, arachnid … |
Dans le fichier des synonymes, on précise les termes synoymes entre eux, sur la même ligne et séparés par des virgules.
Dans cet exemple, le terme "arachnid" est synonyme avec "spider".
Lors d'une requête, l'utilisation de l'un ou de l'autre terme devra renvoyer les mêmes résultats.
Définition des champs
Une fois la description des types définie, on peut procéder à la spécification des champs eux-mêmes. On définit alors le modèle des documents que l'on indexera. L'exemple ci-dessous correspond aux champs donnés en exemple avec le héro Spider-Man :
<field name="id" type="string" indexed="true" stored="true"/> <field name="name" type="text" indexed="true" stored="true"/> <field name="supername" type="string" indexed="true" stored="true"/> <field name="powers" type="text" indexed="true" stored="true" multiValued="true"/> <field name="story" type="text" indexed="true" stored="true"/> <uniqueKey>id</uniqueKey> <defaultSearchField>name</defaultSearchField>
Les champs "name", "powers" et "story" sont du type Text, que l'on a défini plus haut.
Le champ "powers" peut apparaître plusieurs fois, car sa valeur "multiValued" est à vrai.
Lorsque pour un champ, indexed=true, c'est un champ sur lequel on peut effectuer des recherches. Lorsque stored=true c'est un champ qui pourra être retourné lors des requêtes (paramètre "fl").
La clé spécifiée correspond ici au champ "id", et le champ de recherche par défaut est "name".
Analyse
Prenons le cas d'un champ de type Text pour effectuer une analyse lors de l'indexation et d'une requête. Choisissons le champ "powers" :
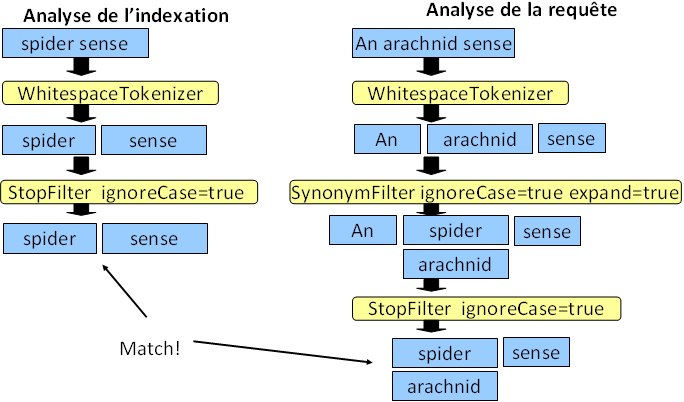
A l'indexation, supposons que le champ "powers" ait comme valeur "spider sense". Tout d'abord, le tokenizer est
appliqué afin de séparer là où il y a des espaces. On obtient donc deux termes, "spider" puis "sense".
On applique ensuite le filtre sur les articles. Etant donné qu'il n'y en a pas, il n'y a pas de différence avec l'étape
précédente, et l'analyse s'arrête là pour l'indexation.
A la recherche, supposons la requête "An arachnid sense". Tout d'abord, on applique le tokenizer selon les
espaces. On obtient donc trois termes différents, "An", "arachnid", et "sense".
Ensuite, on applique le filtre des synonymes, et on trouve que "arachnid" est synonymes avec "spider". Ces deux termes
sont alors conservés.
Enfin, le filtre sur les articles est appliqué en ignorant la casse. Ainsi, le "An" disparaît.
Au final, la requête match, puisqu'on a bien "spider" et "sense" des deux côtés.