Le Grid Computing
Historique
Les origines du Grid Computing
Les origines du Grid Computing sont assez floues, aux alentours des années 70. Certains disent que le précurseur des grilles de calcul est la société Apple, plus précisément l’entreprise NeXT avant qu’elle ne se fasse rachetée par Apple, s’appuyant comme par hasard, sur une idée de Xerox. Le docteur Richard Crandall (NeXT) serait le premier à avoir expérimenté le Grid Computing, grâce à son programme de calcul parallèle distribué baptisé Zilla, le programme utilisait des machines chaînées entre elles pour des traitements mathématiques complexes.
![]()

Le terme de Grid Computing fait son apparition au milieu des années 1990 et s’inspire de la grille d’électricité (power grid). Vers le début du 20ème siècle, la génération personnelle d’électricité était technologiquement possible, et de nouveaux équipements utilisant la puissance électrique avaient déjà fait leur apparition. La véritable révolution a nécessité la construction d’une grille électrique, c’est-à-dire la mise en place de réseaux de transmission et de distribution d’électricité.
Une grille de calcul fonctionne comme un réseau de distribution électrique : celui-ci fournit à chaque utilisateur toutes les ressources dont il a besoin au moyen d'une interface simplifiée, une prise de courant. Toute la complexité du réseau sous-jacent (de la centrale électrique au particulier) est complètement cachée. De plus, l'utilisateur peut faire varier brutalement sa consommation sans démarche préalable. Dans une grille de calcul, puissance de calcul et capacités de stockage sont pratiquement illimitées, puisque toutes les ressources de la grille peuvent être mobilisées en cas de besoin. Elle permet de mettre sans effort en production intensive une application développée localement, et de mieux partager les ressources disponibles (dans les centres de calcul et dans les laboratoires ou bien dans les différents sites d'une entreprise).
Exemple sur l'analogie des réseaux de distribution électrique et du grid computing:
Voici un réseau de distribution éléctrique, avec plusieurs source de production d'énergie et un consommateur d'energie, ce consommateur étant physiquement rélié à ce réseau va pouvoir utilisée l'énergie (les ressources) mise à disposition sans se soucier de quel source provient exactement cette énergie.
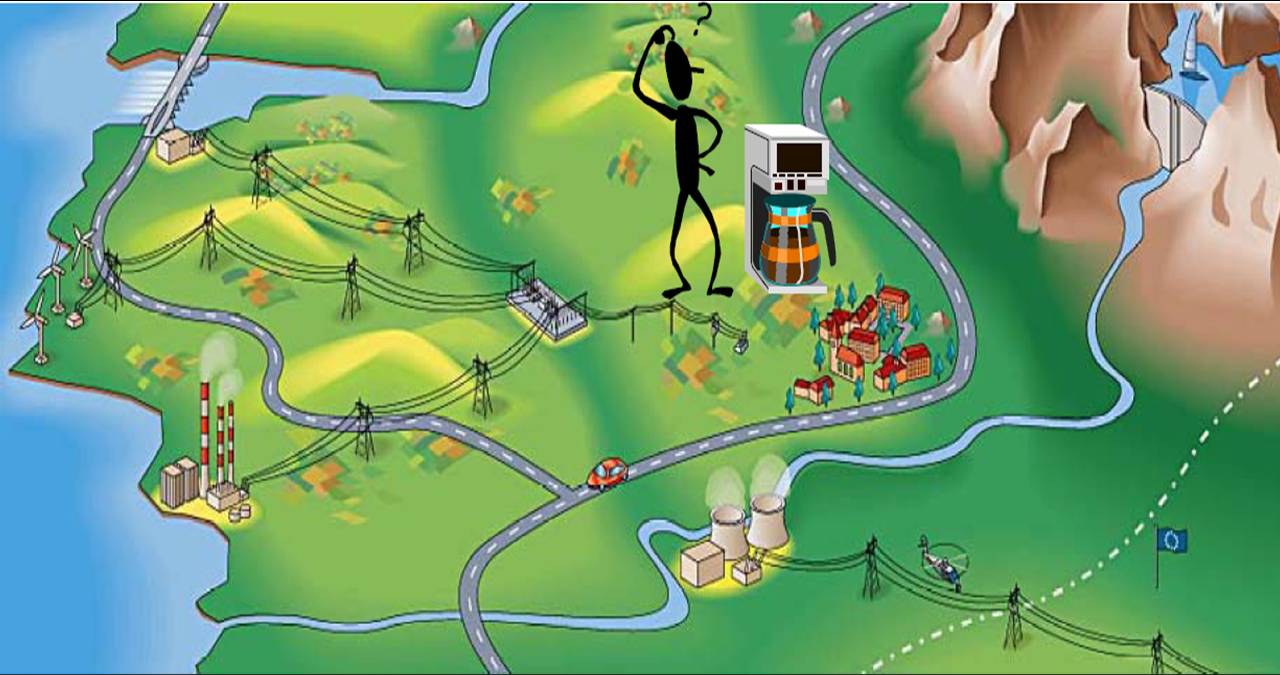
Cette idée est utilisée dans le calcul de grille informatique. Un utilisateur possèdant un ordinateur et nécessitant une énorme puissance de calcul peut, avec le système de grille informatique, soumettre ses tâches à plusieurs "supercalculateurs" enregistrés sur la grille.
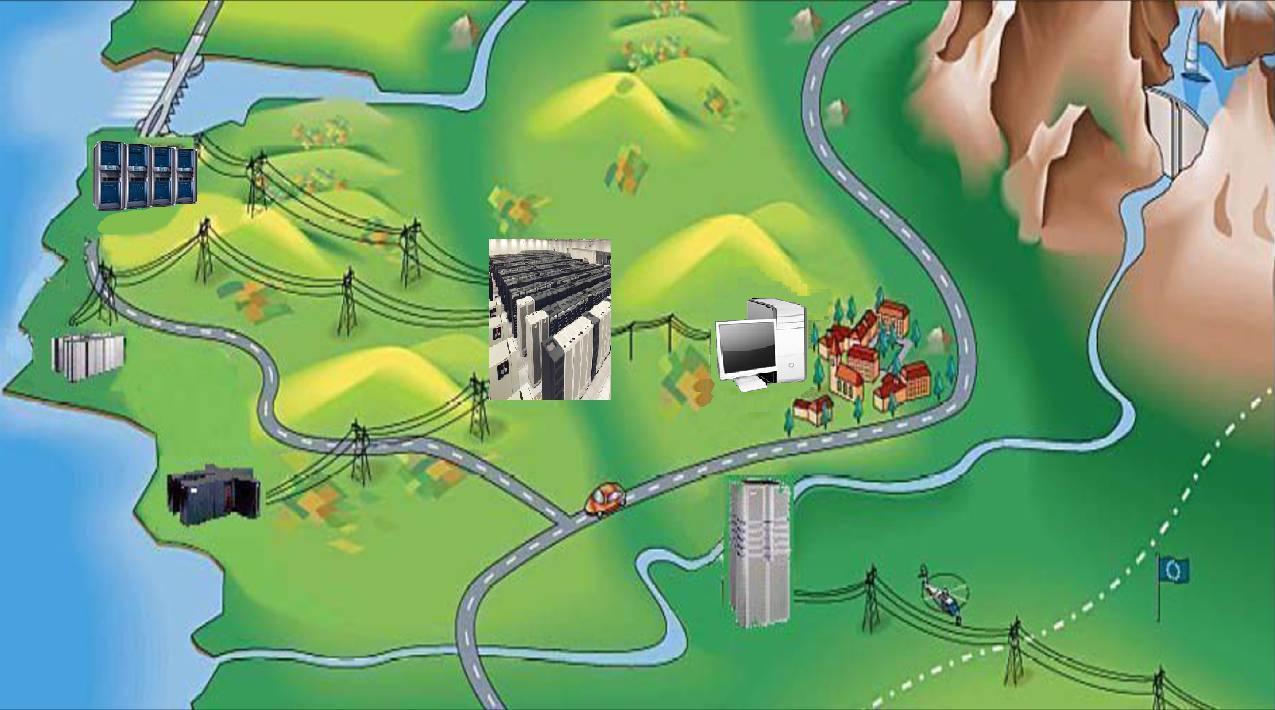
Développpement et évolution
Cette idée de mutualisation des ressources informatiques s’est développée dans le milieu de la recherche scientifique où depuis quelques années, les besoins de puissance de calcul et de traitement des données augmentent démesurément. Cette augmentation se produit alors que le prix des supercalculateurs continue de grimper au point de rendre leur achat trop onéreux.C'est donc en voulant faire des économies que les chercheurs ont décidé d'exploiter ces ressources informatiques délaissées. Ils se sont alors aperçus qu'ils "étaient capables de traiter pratiquement 240 GigaFLOPS (le GigaFLOP correspond à 1 milliard d'opérations en virgule flottante par seconde), soit l'équivalent de quatre serveurs Sun Entreprise 10000, en reliant en interne, 2000 PC de type Pentium cadencés à 166Mhz et une centaine de Pentium III à 4 Ghz, et ce, pour un coût de 200 dollars environ par poste de travail. Il est assez rare qu’une personne disposant d’un PC l’utilise constamment, l’idée de récupérer cette puissance dormante, les cycles de calcul inutilisés.L'apparition des grilles de calcul a été possible avec l'abondance des ressources informatiques (un ordinateur ne coûte plus énormément d'argent et pratiquement chaque foyer en possède un), et leur interconnexion (avec l'avènement d'internet).
Il est devenu possible, de relier, via internet, des équipements géographiquement dispersés et de constituer un réseau qui cumule les capacités de calcul, de stockages, etc, de tous ses membres. Chacun de ceux-ci pouvant alors disposer de la somme des ressources (puissance, mémoire, logiciels, données) apportées par tous les autres participants du réseau, alors que les performances propres de leur micro-ordinateurs ne dépassaient pas celles du marché. C'est ainsi que sont apparues les VO (Virtual Organization). Les Virtual Organizations sont des entités (Entreprises, Instituts, Laboratoires, petits groupes de chercheurs, etc.) qui sont répartis sur divers sites géographiquement différents, et qui mettent en commun leur ressources informatiques (CPU, mémoires, données). Ainsi ils disposent d'une importante puissance de calcul. Mise à part la puissance de calcul mise à disposition de chaque membre de la VO, il y a d'autres avantages à la mise en place d'une Virtual Organization. Un exemple simple est l’exploitation du décalage horaire, lorsque les membres d’un institut virtuel sont repartis un peu partout dans le monde. Un autre avantage de la mise en grille des ressources est la possibilité d’accéder à des bases de données ou à des logiciels distants. On évite ainsi de devoir rapatrier d’énormes quantités de données et le partage de l’achat de coûteux logiciels devient possible. En effet, l’accès à une VO doit être transparent pour l’utilisateur, c’est-à-dire qu’il doit avoir l’impression que la ressource est à côté de lui.