La haute disponibilité logicielle via Heartbeat
S'il faut plusieurs machines en parallèle pour répondre aux requêtes
Il est parfois nécessaire d'avoir plusieurs machines actives en même temps pour répondre à toutes les demandes des
clients. Dans ce cas, il faudra alors mettre en place plusieurs serveurs proposant le même service (disons, au
moins deux), et faire en sorte que les requêtes des clients soient réparties équitablement sur chacun d'entre eux.
Voyons les différentes méthodes pour y parvenir.
Round-Robin DNS
La première approche serait de mettre en place un gestionnaire qui redirigerait les requêtes de manière
équiprobables entre toutes machines proposant le même service.
Voici le schéma correspondant :
C'est une méthode qui a fait ses preuves, et qui est par exemple utilisée pour les serveurs de noms (serveurs DNS).
Le mécanisme utilisé s'appelle 'Round Robin'.
L'intérêt d'une telle méthode est que si l'une des machines tombe en panne, les utilisateurs seront redirigés de
manière totalement transparente vers la seconde, sans même s'en apercevoir. Ce qui est parfait.
Mais il est possible de faire mieux. En effet, ceci est certes intéressant, mais ne prend pas en compte la
puissance ou la disponibilité de chaque machine utilisée pour répondre aux requêtes.
C'est ici qu'intervient la répartition de charge.
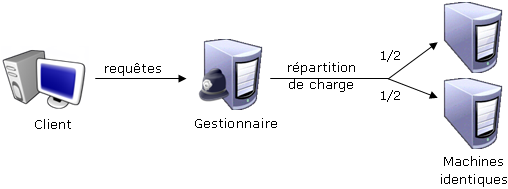
Load Balancing (Répartition de charge)
L'avantage d'un répartiteur de charge par rapport au 'Round Robin', est qu'il est capable de répartir équitablement
les connexions sur toutes les machines, en tenant compte de la puissance de celles-ci, et du nombre de personnes
déjà connectées.
Le schéma correspondant pourrait être :

Il existe plusieurs algorithmes de répartition. Voici ceux utilisés par The Linux Virtual Server, un outil de répartition des connexions TCP et UDP :
- Least-Connection (lc)
- Envoyer la requête vers la machine ayant le moins de connexions à ce moment là.
- Weighted Least-Connection (wlc)
- Envoyer la requête vers la machine ayant le moins de connexions, en favorisant de préférence telle ou telle machine en fonction de son poids par rapport aux autres
- Round-Robin (rr)
- Envoyer les requêtes à chaque serveur tout à tour, de manière circulaire.
- Weighted Round-Robin (wrr)
- Comme précédemment, en favorisant de préférence telle ou telle machine, en fonction de son poids.
- Locality-Based Least-Connection (lblc)
- Essayer d'envoyer toutes les requêtes venant de la même IP source au même serveur à chaque fois, tout en favorisant les machines avec le moins de connexions.
- Destination-Hashing (dh)
- Renvoie les connexions des clients vers des serveurs spécifiques, en regardant dans une table de hachage l'adresse du serveur de destination.
- Source-Hashing (sh)
- A l'inverse, regarde dans la table de hachage vers quel serveur envoyer le client, en fonction de l'adresse source de celui-ci.
- Shorted Expected Delay (sed)
- Envoyer les requêtes vers le serveur qui doit statistiquement répondre le plus vite.
- Never Queue (nq)
- Envoyer une connexion vers un serveur inutilisé lorsque c'est possible, sinon utiliser l'algorithme "Shorted Expected Delay".
Un gestionnaire unique devient un point de faiblesse
Avec tous ces algorithmes accélérant le traitement des requêtes, le répartiteur de charge semble donc être la meilleure méthode pour faire de la haute disponibilité. Mais que ce passe t-il si ce serveur tombe en panne ? Plus aucun mécanisme ne fera le lien entre les requêtes du client et les autres machines, et plus rien ne fonctionnera :

Pour éviter cela, il faudra mettre un second gestionnaire qui surveillera le premier. Si celui-ci tombe en panne,
l'autre devra le détecter et prendre sa place, devenant ainsi le gestionnaire principal.
Les lecteurs attentifs (ou ceux qui ne sont pas encore perdus, c'est selon) auront certainement remarqué que ce n'est ni plus
ni moins qu'un cas de haute disponibilité où une seule machine est active à la fois.
Le schéma final ressemblera donc à ceci :

Ouf. On a cette fois-ci une solution parfaite, qui permet à n'importe quelle machine de tomber en panne sans que l'ensemble n'en soit pénalisé. Il reste toutefois un dernier détail réseau à régler, et tout sera dit : la mise en place d'une IP virtuelle.