Google AltaVista Yahoo! HotBot Lycos Northern-Light Kartoo MSN Netscape AOL Deja Excite Go
InfoSpace AllTheWeb LookSmart Dmoz AskJeeves DirectHit Inktomi Iwon DogPile Overture NBCi
|
|
||||||||
|
-[Bien Chercher]-
-[Benchmarking]-
-[Bien Trouver]-
|
||||||||
|
|
|
-[Bien Trouver]- |
|||||||||||||
|
Point 25
: Introduction
Term Frequency (TF) :
l’importance d’un terme t est proportionnelle à sa fréquence dans
un document
Inverse Document Frequency : les termes qui apparaissent dans peu
de documents sont intéressants
IDF est censé améliorer la précision Mais Salton a montré que les meilleurs résultats
étaient obtenus en multipliant TF et IDF : TDIDF(t,i)
= TF(i,t) * IDF(t)
TDIDF = (frequence(m, d) * log(N/n)) / Racine ( Somme sur termes
t(tf²(t,d) * log²(N/t)))
Remarque :
le modèle vectoriel de Salton propose de représenter chaque document par
un vecteur. Soit N le nombre total de termes distincts dans la
collection (appelé encore le vocabulaire), on représente chaque document
par un vecteur de N éléments. Bien sûr, N est généralement très
supérieur au nombre réel des mots présents dans un document. Il en
découle que le vecteur contient beaucoup de 0. Pour gagner en place, on
représente un document par la liste des termes qu’il contient, avec
l’indice du terme. Si le document contient les termes numéro 25, 500 et
768, avec des fréquences respectives de 5,10 et 7, on associera au
document la liste de couples (indice,fréquence) suivante : (25,5)
(500,10) (768,7). On doit ensuite choisir une fonction de Distance
(ou au contraire de Similarité) qui permet de comparer les documents
deux à deux. Voici quelques exemples couramment utilisés et extraites de
la littérature en recherche d’information : Simple(i,j)
= |Intersection(i,j) où Intersection = les mots communs aux
documents i et j Dice(i,j) =
|Intersection(i,j)| / (|i| + |j|)
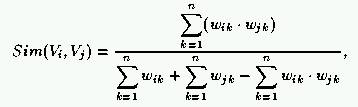
Jaccard(i,j) = |Intersection(i,j)| / |Union(i,j)|
Ce qui revient (avec le modèle vectoriel) :
Cosine(x,y) = Somme 0..n(xi * yi) / Racine (Somme 0..n(xi²)
* Somme 0..n(yi²))
Remarque : on n’est pas obligé de normaliser avec la division : on
peut se contenter de Somme(xi,yi) Euclidian(x,y)
= Racine( Somme 0..n((xi-yi)²) ) Opérations facultatives :
Remarquons que cette représentation des documents
perd l’information sur la position des mots. De plus, elle ne repère pas
les co-locations de mots, par exemple “ word wide web ”. Mais il est
parfaitement possible de prendre en compte les co-locations : il suffit
de générer tous les couples, ou les triplets, etc. des mots qui
apparaissent dans les documents. Notons que cette étape augmente le
nombre de termes et ajoute du temps de calcul (Maarek utilise une
technique “ window sliding ” qui n’ajoute pas trop de temps de calcul).
Maarek utilise les couples de mots (qu’il baptise “ lexical affinities ”)
pour classer des bookmarks et l’emploi des co-locations tend à améliorer
la précision de la classification. Notons enfin que des recherches récentes ont montré
l’intérêt d’utiliser le format des documents HTML pour enrichir la
représentation des documents. Typiquement, les mots présents entre des
tags <H1> <H2> ... sont a priori plus important et sont donc représentés
comme tels (pondération plus grande que les autres mots). Finalement, selon l’algorithme de clustering
utilisé ensuite, le nombre de mots utilisés peut s’avérer très
problématique pour les temps de calcul. A titre d’exemple, une simple
base d’annotations portant sur 300 documents contient environ 3000 mots
distincts (sans compter les mots enlevés par stoplist et les mots
inférieurs à 3 lettres), soit une moyenne de 10 mots surlignés par
document. Même avec ce faible nombre de termes, une matrice de
similarité nécessite en théorie 3000 * 300 entiers, soit 3.5 Moctets de
mémoire (entiers codés sur 32 bits, ou encore 4 octets). Les méthodes
courantes de sélection de mots se basent sur des critères de fréquence.
Les mots les plus fréquents sont gardés et les autres sont éliminés.
Attention : cette méthode est bien sûr imparfaite car un mot peut
fréquent pourrait bien être important pour représenter une catégorie ! A
titre d’exemple, nous citons ici quelques méthodes de réduction du
nombre de termes : Latent Semantic Indexing et SOM (voir plus loin).
|