In [1]:
from bs4 import BeautifulSoup as bs
In [2]:
from urllib.request import *
In [3]:
u = 'http://igm.univ-mlv.fr/~jyt/M1_python'
In [4]:
s = urlopen(u).read()
In [5]:
s
Out[5]:
In [6]:
# Touillage d'un mot comme dans le TD2
import random, re
p = re.compile('(\w)(\w\w+)(\w)', re.M)
def touille(m):
milieu = list(m.group(2))
random.shuffle(milieu)
return m.group(1) + ''.join(milieu) + m.group(3)
In [9]:
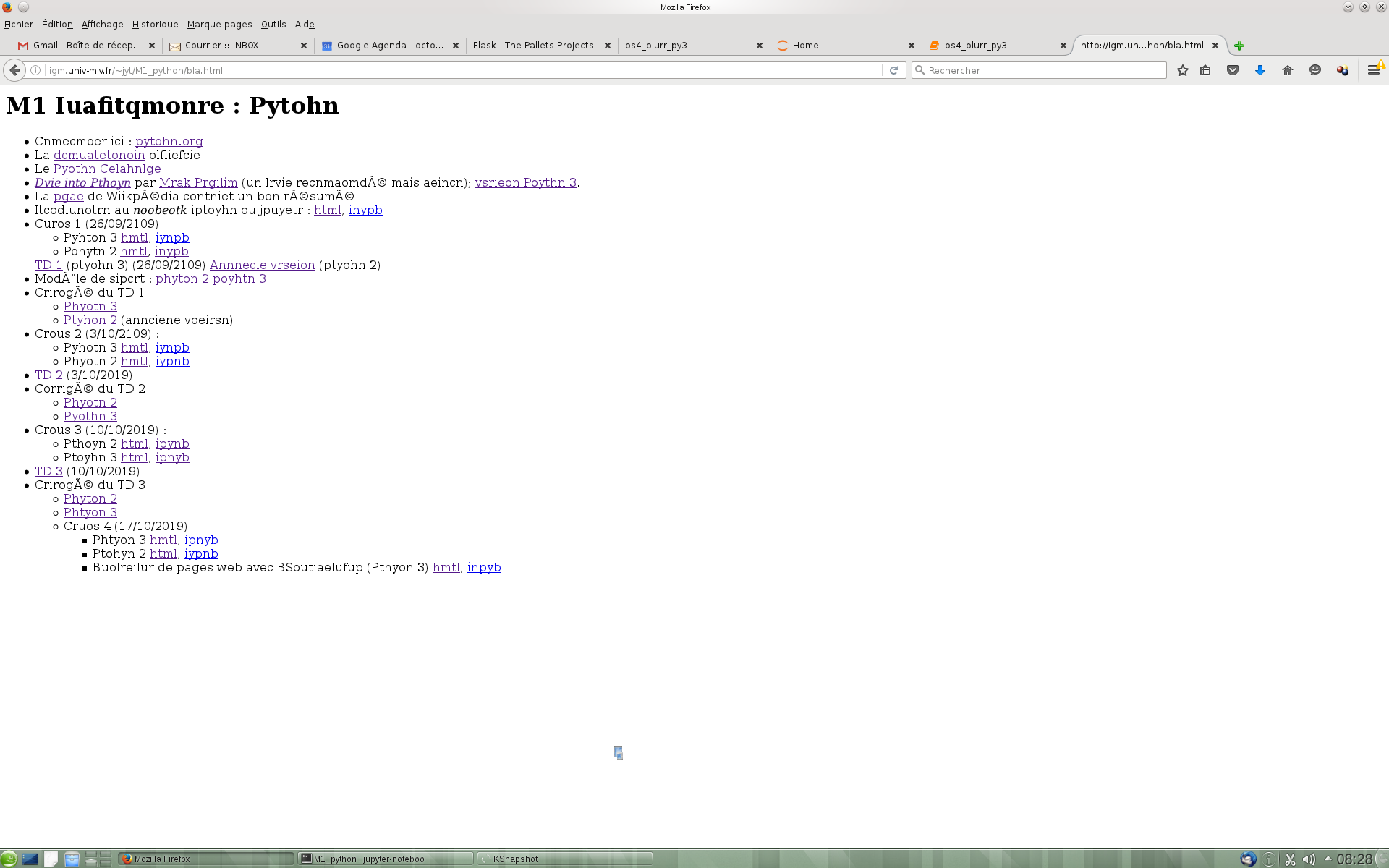
# Pour commencer, on ne modifie que le texte
# Pour surcharger handle_data, on créee une classe dérivée de BeautilfulSoup
class mySoup(bs):
def __init__(self,s):
bs.__init__(self,s)
def handle_data(self,x):
self.current_data.append(p.sub(touille,x)) # !!!
In [10]:
soup = mySoup(s)
In [31]:
print soup.getText()
In [11]:
# pour visualiser, on sauvegarde dans un fichier
open('bla.html','w').write(str(soup))
Out[11]:
In [12]:
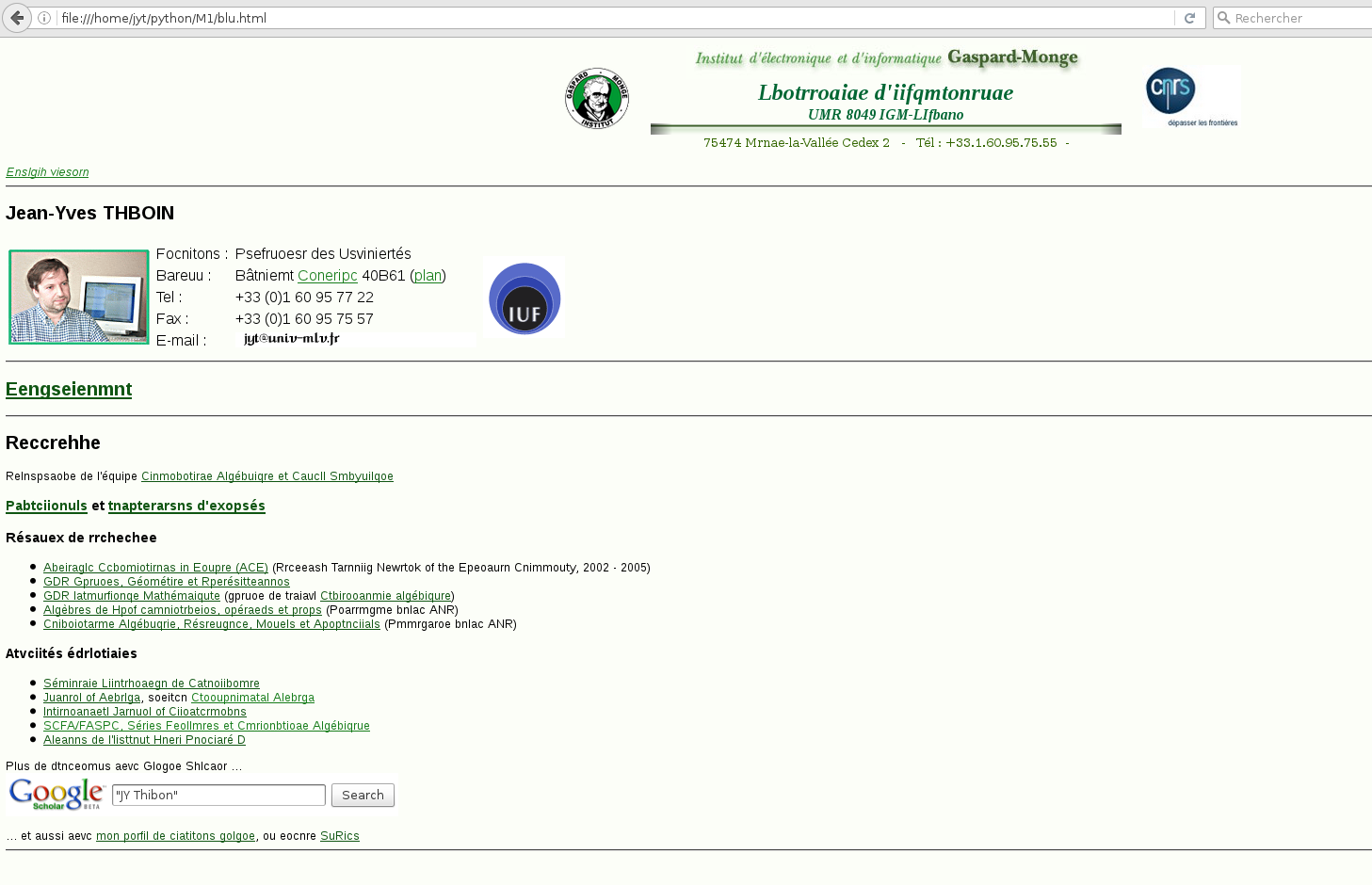
# Pour récupérer des liens fonctionnels et les images,
# il faut maintenant surcharger handle_starttag
# On se contentera des attributs href et src,
# mais il resterait beaucoup d'autres cas à prendre en compte pour être complet.
from urllib.parse import urljoin
class newSoup(mySoup):
def __init__(self,s,u):
self.url = u
mySoup.__init__(self,s)
def handle_starttag(self,name,namespace,nsprefix,attrs):
if 'href' in attrs: attrs['href'] = urljoin(self.url,attrs['href'])
if 'src' in attrs: attrs['src'] = urljoin(self.url,attrs['src'])
mySoup.handle_starttag(self,name,namespace,nsprefix,attrs)
In [13]:
u ='http://igm.univ-mlv.fr/~jyt/'
s = urlopen(u).read()
soup=newSoup(s,u)
In [14]:
open('blu.html','w').write(str(soup))
Out[14]:
In [ ]: