suivant: org.apache.lucene.documen monter: Architecture et Organisation de précédent: org.apache.lucene.utils Table des matières Index
Ce paquetage contient les classes pour convertir du texte en élément indexable.
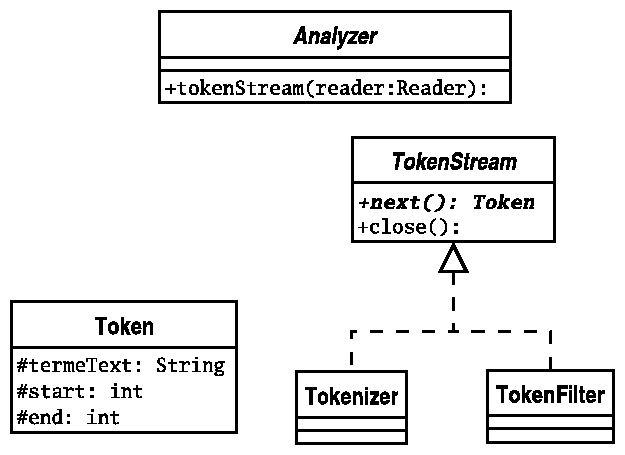
Un Analyser (classe abstraite) fabrique des tokenStream à partir d'un flux de caractère.
Un TokenStream (qui est une classe abstraite) est une suite de Token
Un Token est une portion d'un texte. Par exemple dans le texte "oui je suis un texte", on peut définir le Token , ayant pour texte "oui je suis un texte",de début 4,de fin 6 et de type "word". Ce token représentera le mot "je".
Il peut y avoir plusieurs types de TokenStream qui je le rappelle est une suite de token :
Exemple de filtres : LowerCaseFilter convertit chaque terme d'un tokenstream en minuscule. PorterStemFilter filtre selon l'algorithme de Porter Stemmer. GermanStemFilter extrait les mots selon la grammaire allemande par exemple tout les tokens se terminant pas en, ed et er sont tronqué (déclinaison d'un mot en Allemand). StopFilter permet à partir d'une liste de mot de déterminer supprime de la séquence de mot ceux de la liste.
Il existe donc des Analyser pour des types de Tokenizer qu'on pourrait construire.... exemple : StandardAnalyser combine un StandardTokenizer, un StandardFilter, un StopFilter et un LowerCaseFilter.