
Couche par couche les outils de développement
Après avoir étudié le cheminement qui a amené aux architecture n-tiers, nous allons maintenant étudié chaque partie en détail en étudiant une partie des outils qui permettent de les développer. Le schéma ci-dessous montre couche par couche certaines de ces technologies.
Les outils par couches
Afin de présiser
les rôle de chacune des parties nous agrémenterons notre présentation
avec l'exemple d'un moteur de recherche que nous avons développé
en suivannt une architecture 3 tiers.
Le niveau 1 est chargé des interactions avec l'utisateur. C'est l'interaction Homme-machine. On appelle en général ce niveau "présentation".
Il ne doit comporter ni donnée ni traitement car il doit être facilement modifiable. En particulier on veut permettre une évolution de cette interaction avec l'utilisateur sans avoir à modifier les données applicatives. On souhaite par exemple pouvoir changer de station cliente aisément.
En effet aujourd'hui les grandes entreprises souhaitent ouvrir leur système d'information a leur fournisseur et leur client. Les systèmes d'informations ont donc tendance à grossir et a être de plus en plus hétérogène ( dans le trio précédent chacun peut utiliser des techniques différentes ). D'autre part la multiplication des outils permettant d'acceder au système d'information a aussi été déterminante dans le choix du client léger. En effet on se connecte au SI aussi bien à partir d'un PC, d'un mac que d'un téléphone mobile ou d'un organiseur personnel. Pour pouvoir répondre aux égigences de ces différentes plateformes c'est le navigateur qui a été choisi.
Les navigateurs ont a peu prêt le même usage que les terminaux dédiés des anciennes applications client-serveur. Leur fonctionnement est similaire quelques soit le propriétaire du navigateur. Ils permettent d'homogéneiser les interfaces graphiques d'un SI et existe sur les différentes plates formes dont nous avons parlés précédemment.
Le navigateur permet d'avoir un client léger, cependant certains traitement doivent être effectué dans le niveau présentation, c'est par exemple le cas de l'affichage des pages ou encore de la création de ces pages. C'est pourquoi on associe un serveur Web au navigateur. Son role est essentielle à l'architecture. C'est lui qui relie le poste de l'utilisateur au système d'information de l'entreprise. Il peut en particulier contenir la machine virtuel java.
La station de travail assure uniquement le dialogue entre le navigateur et le serveur web. Le server web génére les pages HTML dynamiquement a partir d'informations des serveurs applicatifs ou des applications autres de l'entreprise. La mise en oeuvre de ces pages dynamiques peuvent s'effectuer à partir de différentes technologie.
On peut citer, CGI, Servlet-JSP, PHP, ASP-activeX. Ces différentes technologie sont des technologies coté serveur. Elle ne demande aucun travail du client. Les CGI ( Common Gateway Interface ) ont été les premières technologies de ce type. Ce sont des programmes exécutés cotés serveurs qui permettent l'affichage de données traitées par le serveur ( provenant d'autre application comme une base de donnée par exemple ). Leur grand intéret et d'offrir des pages dynamiques en fonction par exemple d'un choix de l'utilisateur. Les autres technologies cités ci-dessus sont la réponse des fournisseur de langages informatique aux CGI
On peut schématiser la partie présentation par ce schéma:

.
L'exemple de la couche présentation du projet glooton
Dans un moteur de recherche la partie présentation représente l'IHM de l'application. Le schéma ci-dessous présente le diagramme de séquence du Use case recheche pour le niveau 1. Ce Use case débute lorsque un utilisateur entre une requete et se termine lorsque les résultats de la requête sont affichés.

Niveau présentation de glooton.
Pour ce projet nous avons choisi les technologies offertes par JAVA ( le couple servlet-JSP ).
Elles sont au serveur Web ce que les applets sont au navigateur pour le client. Les servlets sont donc des applications Java fonctionnant du côté serveur au même titre que les CGI et les langages de script côté serveur tels que ASP ou bien PHP. Les servlets permettent donc de gérer des requêtes HTTP et de fournir au client une réponse HTTP dynamique (donc de créer des pages web dynamiques).
Elles offrent de nombreux avantages par rapport aux autres technologies côté serveur. Tout d'abord, étant donné qu'il s'agit d'une technologie Java, les servlets fournissent un moyen d'améliorer les serveurs web sur n'importe quelle plateforme, d'autant plus que les servlets sont indépendantes du serveur web (contrairement aux modules apache ou à l'API Netscape Server). En effet, les servlets s'exécutent dans un moteur de servlet (parfois appelé conteneur de servlet) utilisé pour établir le lien entre la servlet et le serveur web. Ainsi le programmeur n'a pas à se soucier de détails techniques tels que la connexion au réseau, la mise en forme de la réponse à la norme HTTP, ...
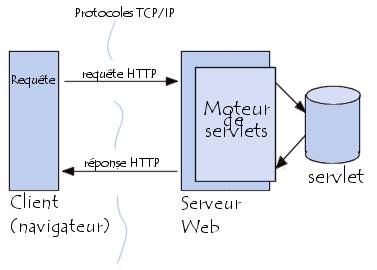
Les Servlets
Les JSP (Java Server Pages) sont un standard permettant de développer des applications Web interactives, c'est-à-dire dont le contenu est dynamique. C'est-à-dire qu'une page web JSP (repérable par l'extension .jsp) aura un contenu pouvant être différent selon certains paramètres (des informations stockées dans une base de données, les préférences de l'utilisateur,...) tandis que page web "classique" (dont l'extension est .htm ou .html) affichera continuellement la même information.
Il s'agit en réalité d'un langage de script puissant (un langage interprété) exécuté du côté du serveur (au même titre que les scripts CGI,PHP,ASP,...) et non du côté client (les scripts écrits en JavaScript ou les applets Java s'exécutent dans le navigateur de la personne connectée à un site).
Les JSP sont intégrables au sein d'une page Web en HTML à l'aide de balises spéciales permettant au serveur Web de savoir que le code compris à l'intérieur de ces balises doit être interprété afin de renvoyer du code HTML au navigateur du client.
Ainsi, les Java Server Pages s'inscrivent dans une architecture 3-tier. Un serveur supportant les Java Server Pages peut servir d'intermédiaire entre le navigateur du client et une base de données en permettant un accès transparent à celle-ci. JSP fournit ainsi les éléments nécessaires à la connexion au système de gestion de bases de données, à la manipulation des données grâce au langage SQL.
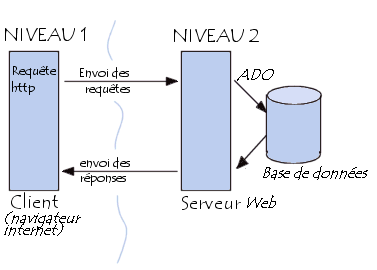
Les JSP dans une architecture 3-tier
L'utilisation des Servlets et des JSP dans Glootons
Dans notre moteur de recherche nous avons combinés l'utilsation des servlets à celles des JSP. L'utilisation combinées de ces deux technologies ce fait de la façon suivante.
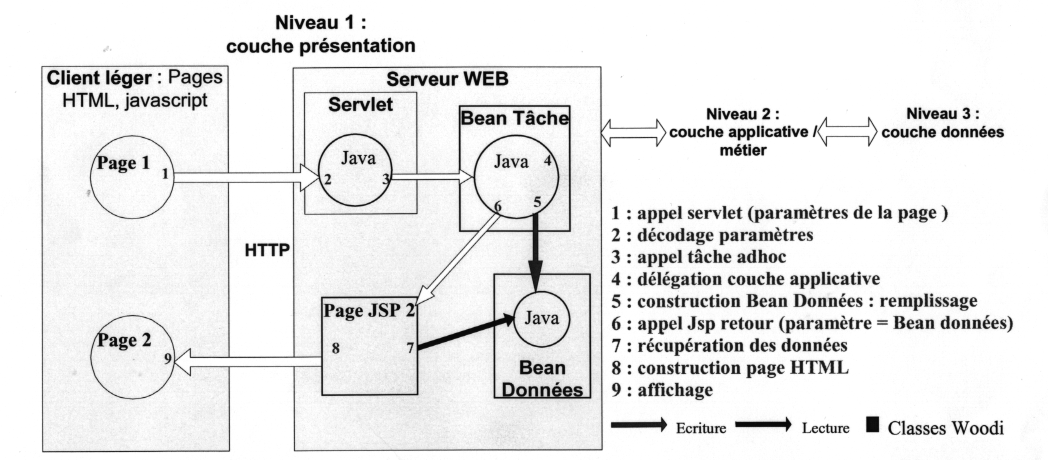
Utilisation des Servlets et des JSP dans le niveau 1.
On peut constater sur ce schéma que les différentes parties du logiciels communiquent entre elles à l'aide Bean Java. Ces beans sont en fait des containers. Il possède des attributs propres et des accesseurs sur ces attributs. Ils font l'objet d'une norme stricte qu'ils doivent respecter pour être utiliser dans les différentes parties.
Le niveau 2 est dit niveau "applicatif". Il met en oeuvre le différentes règles de gestion de l'application, on parle aussi de processus métier. Il est l'interface entre l'IHM et les données pérennes de l'entreprise.
Ce niveau 2 est composé de 1 à n serveurs applicatifs ( 1 -> architecture 3 tiers, n -> architecture n-tiers ).
Les serveurs applicatifs ne contiennent aucune donnée pérennes, il peut cependant posséder des variables locales mais celles-ci ne seront pas accéssible par les autres applications et seront volatiles. Elles ne feront donc l'objet d'aucune sauvegarde.
Il faut noter qu'un serveur applicatif ne correspond pas forcément à une machine physique.mais à un serveur logique. A un serveur logique correspond une application.
Ces serveurs doivent être conçu à base d'objet. C'est d'ailleurs un objet à part entière à forte granularité, on peut utiliser ces services mais on cache aux utilisateurs la construction de ces serveurs. De plus en plus de serveur applicatif utilise les EJBs pour permettre cette granularité.
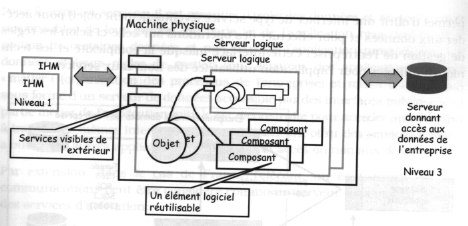
La couche applicative: un objet
Comme nous l'avons vu ce niveau englobe toutes les specificités métiers de l'application, certains de ces éléments peuvent être réutilisables mais en général ils sont très liés à l'application. On peut ainsi réutiliser les méthodes d'accés au niveau 3. En effet c'est dans ce niveau que se trouve les méthodes d'accés au niveau 3 et en particulier aux base de données. L'accés aux bases de données s'effectue à l'aide d'interface générique permettant un accès standard aux différentes base de données. On appelle ces interfaces des CLI( Call Level Interface ).
La première interface de ce type s'appelait SAG, il avait été crée 1988 par quarante quatre éditeur de base de données. Le but était de permettre à tous clients SQL de communiquer avec tous serveurs SQL. En 1992 Microsoft a crée l'ODBC ( Open DataBase Connectivity ) qui est la réponse prête à l'emploi pour l'accés aux bases de données sous windows. Microsoft a ensuite vendu des interfaces a certains éditeurs pour le permettre d'utiliser ODBC sur des plates-formes non-Windows.
Avec le développement des langages orientés les différentes CLI se dirige elles aussi vers des interfaces objets. Les deux pricipales sont JDBC et ADO ( ActiveX Data Object ). Avec ces deux CLI ont peu accéder aux différentes bases de données par des interaces objet au lieu de procedure. Enfin elles peuvent être utiliser avec les ORB du commerce.
JDBC (Java DataBase Connection )
C'est la CLI de JavaSoft. Ecrite en java elle est donc totalement portable. Elle permet d'écrire du code java indépendament des SGBD. Elle fournit 2 jeux d'interfaces, une interface application qui permet l'accés aux services SQL, une interface de pilote que les éditeurs doivent adapter à leurs bases de données particulières.
Dans notre moteur de recherche nous avons utilisé JDBC. Dans le schéma suivant on peut voir comment on crée une requete SQL à partir desz objet applicatif. On appelle fabrique les objets permettant de créer une requête à partir de ces objets.
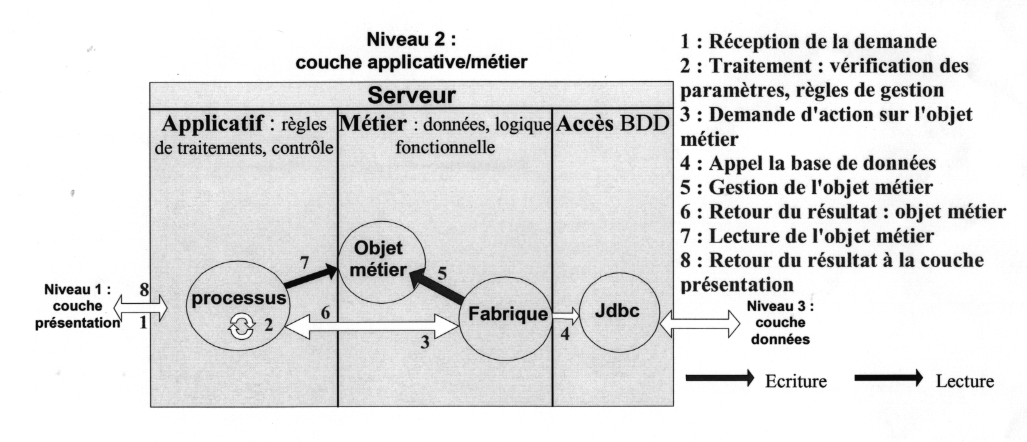
création d'une requête SQL dans la couche applicative
La couche applicative du projet glooton
La partie applicative de notre moteur de recherche comprend plusieurs fonctionalités suivantes:
Le schéma ci-dessous montre le diagramme de séquence de la couche application.
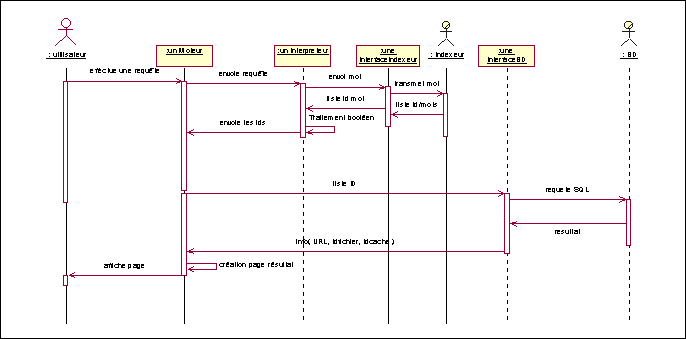
Diagramme de séquence partie applicative
C'est le niveau des données. Elles peuvent êtres les données de l'entreprises ou les données des applications patrimoniales. Ils contient des plus les traitements et les opération uniquement liées à ces données. Les applications applications patrimoniales se trouve dans ce niveau car elles offrent car elles offrent l'accés aux données qu'elles gèrent. Ces données et leur traitement sont pérennes.
Ce niveau est essentiellement constitue de serveur de base de données. Celles-ci peuvent être relationnelle ou objet.
L'intérrogation des bases
de données relationnelles peuvent se faire de plusieurs manières.
La première est celle que l'on a étudié dans le niveau
2 c'est à dire utiliser une CLI.
La seconde consiste à utiliser des procedures stockés qui sont
offertes par différents éditeurs( Oracle, Sybase et bien d'autres
). Ce sont des des ensembles déterminées de commandes SQL et de
procédure logique qui sont compilées, vérifiées
et rangées dans la base de données. On parle aussi de transactionnel
léger. Les procédures stockés permettent une réduction
de la charge du réseau et optimise les temps de réponses.
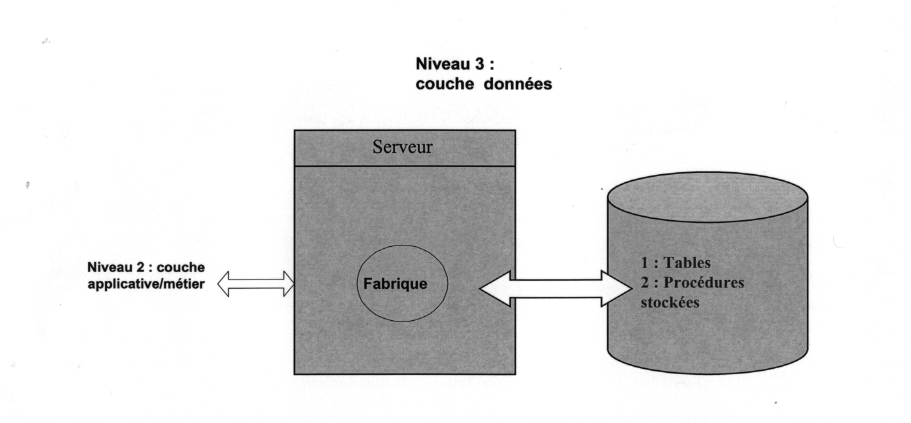
La couche donnée
Enfin la dernière méthode est l'utilisation de moniteurs transactionnels et les objets nous nous attarderons plus sur cette dernire partie dans le chapitre middleware.
Les bases de données Objet utilisent les définitions de classes et les constructeurs des languages objet usuels( C++, Java... ) pour définir et accéder aux données. Ceci permet de ne pas utiliser d'intermédiare entre le langage de programmation et la base de données. Elles sont principalement utiles pour les données difficilement simples pour être alignés dans des tables relationnelles. Comme les bases de données classique elles gèrent la concurrence d'accés, offrent des verroux et assure la protection des transactions. La principale différence entre les SGBDO et les bases de données classiques provient du fait qu'elles stockent directement des objets et non des tables.On peut citer Object Design, Versant, UniData qui a remplacé O2....
La couche donnée du projet glooton
Dans notre moteur de recherche nous avons opté pour la base de donnée libre postgrey. Notre logiciel n'étant pour le moment qu'un prototype non optimisé nous n'avons pas utilsé de procédure stocké mais la CLI JDBC. Ce choix est principalement dues au fait que nous possédions des compétences en java nous permettant de développer cette partie plus rapidement.
Le middelware fédérateur de l'architecture
Nous avons étudié séparément chacune des parties d'une application n-tiers. Pour former une application à part entière ces parties doivent être relié entre elles. Or chacune elles peuvent se trouver sur différents serveurs physique ou encore utiliser des technologies différentes. Les différents serveurs sont regroupés entre eux par un réseau sans couture qui fournissent des tuyaux fiables et performants. Afin d'effectuer la liaison entre les différentes parties du logiciel tout en rendant le réseau transparent aux utilisateurs ont utilise un middleware. Ce sont des environnementsd'informatiques distribués qui masque les contraintes réseaux aux utilisateurs.
En plus de masquer le réseau on masque aussi l'OS des différentes machines ce qui permet de faire travailler ensemble des serveurs basés sur des OS différents.
On distingue en général quatres types de middleware différents:
Il permet d'échanger des messages
entre un client et un serveur au moyen de file d'attente de messages. Les applications
communiquent sur le réseau en disposant et en retirant des messages dans
des files d'attentes. C'est un middleware qui fait abstraction de la couche
communication. Il autorise des executions désynchronisée des applications
et n'impose pas de connexions entre elles.
Ce type de middleware est particulièrement adaptés aux situations
où une connexion entre client et serveur n'est pas souhaitable pour des
raisons de sécurités ou d'efficacité. Ils offrent enfin
deux modes de communications:
Avec ce type de middleware les application transmette les messages à des destinations, qui sont des files d'attente. Elles n'ont pas connaissance de la location physique de ces destinations ni des noms des application. Un message peut être transmis à plusieurs destinataires.
Plusieurs MOM existe sur le marché comme MQSeries d'IBM ou MessageQ de BEA.
Je vais tout d'abord préciser ce que l'on appelle transaction ou unité de travail.C'est une suite d'action qui changent l'état de manière controllé. Il n'y a pas de demi-mesure, soit le travail a été effectué soit non. Si pour une raison quelconque la transaction n'a pu se terminer, on replace le système dans son état de départ. Une transaction a un début et une fin que l'on doit obligatoirement atteindre pour que les modifactions soit validées. Une transaction possède 4 attributs principaux:
Un MOT est un environnement réparti qui prend en charge l'execution d'une application et la verification de son bon fonctionnement en intégrant des mécanismes transactionnels. En plus des aspects purement transactionnels, ils offrent un outil de gestion optimisé et partagé des ressources, un outil de communication et un outil d'administration et de supervision.
Les MOT permettent au programmeur de ne pas s'occuper des problèmes de simultanéités d'accès, de défaillance du système, de ruptures de connexions. Ils fournissent le moteur pour faire tourner les applications au dessus des OS et du matériel. Ils assurent une cohérence transactionnelles et facilite le découpage des applications en services.
Il existe différents moniteurs transactionnels comme Tuxedo de BEA ou CIS d'IBM
Pour permettrev à différentes applications de communiquer entre elles, il faut des règles et des formats commun d'appels de services pour permettre aux différents objets de communiquer entre eux car les composants peuvent être de nature différentes. Tout d'abord il peuvent être sur des machines différentes ayant des OS différents. Ils peuvent aussi avoir été conçu dans des langages différents.
Ils existe trois modèles de composants objets qui sont complémentaires et interopérable. Il s'agit du modèle CORBA, des composant Java EJB et enfin de DCOM de microsoft.
CORBA ( Common Object Request Broker Architecture ) est le produit d'un consortium appellé OMG( Object Management Group ) comprenant plus de huit cent entreprise represantant le spectre le plus large de l'industrie informatique. Microsoft qui possède son propre bus à objet DCOM est une des principales exception.
C'est une spécification, il définie un standard permettant de faire collaborer des applications disposées sur des machines, des environnements et des langages différents. Il permet le développement de composants objets et leurs intéractions dans une application distribuée et les appels à des services normalisés. Ces composants peuvent être développé avec différents langages orientés objet( C++, SmallTalk, Java ).
L'architecture CORBA est basée sur un bus appellé ORB ( comme Object Request Broker ). L'ORB est l'élément central de cette architecture. Il permet aux objets d'émettre de façon transparente des requêtes déstinées à d'autres objets, locaux ou distant, et d'en recevoir les réponses. Il fait office de routeur entre les composants, qu'elle que soit leur localisation et indépendamment des protocoles de réseaux, il est outre capable d'activer le destinataire de réponse. Le client ne connait pas les mécanismes utilisés pour communiquer avec les objets serveurs, pour les activer ou les stocker.CORBA offre un ensemble de service très riche. Pour communiquer au travers du bus les objets doivent être munis d'une interface au standard IDL ( Interface Definition Langage ). L'OMG a spécifié un protocol pour assurer la communication entre les objets: le protocole IIOP ( Internet Inter-Orb Protocole ). Ce protocole offre l'avantage de permettre à deux ORB provenant de constructeur différent de dialoguer en masquant les couches de communications.
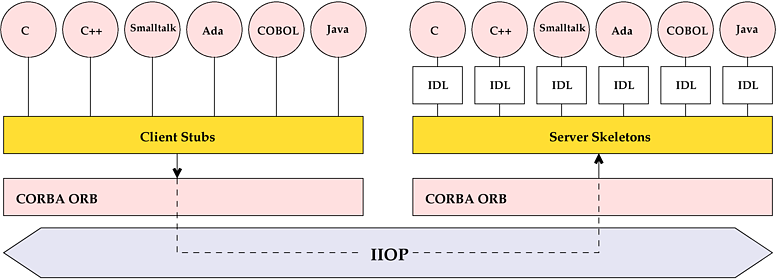
Comme nous l'avons vu CORBA est une spécification et non un langage c'est pourquoi plusieurs éditeurs sont présents sur le marché CORBA: c'est le cas d'Inprise avev Visibroker, d'Orbix Web de Iona ou encore JavaOrb qui est un ORB libre.
DCOM est une plate-forme de communication développée par Microsoft.
Microsoft a été un des premiers membres de l'OMG, bien avant que le Web ne représente l'enjeu économique qu'il est aujourd'hui. Aux débuts de CORBA, Microsoft s'impliqua peu, avant de décider plus tard que CORBA entrait en concurrence de manière trop directe avec les projets qu'ils avaient pour DCOM.
DCOM est une extension distribuée de COM : "Distributed" COM. C'est à dire l'élargissement du concept COM sous forme d'objets distribués. COM était quant à lui une évolution de OLE, une technologie permettant les applications Windows d'interagir entre elles. Microsoft voyait en DCOM la possibilité d'étendre sa domination des postes clients au niveau du réseau. Tout cela dans le but d'imposer Windows comme un standard de facto nécessaire à toute architecture distribuée.
COM a été créé à un moment où les architectures distribuées n'étaient pas nées. Donc DCOM a été obligé de supporter toutes les contraintes de COM et ses lacunes de conception. Par exemple il est impossible d'accéder directement à un objet particulier, car aucun mécanisme d'identification des objets n'existe. Il est uniquement possible d'accéder à des interfaces particulières et non à des instances. Dans un autre registre, manipuler DCOM à un haut niveau d'abstraction est facile, mais il devient très dur de manipuler cette architecture lorsqu'on veut s'approcher des plus bas niveaux d'abstraction.
Vous avez sûrement déjà entendu parler des ActiveX, et vous vous demandez ce que ça peut bien être. Et bien les ActiveX sont des objets DCOM. A moins de vouloir restreindre son architecture à des PCs fonctionnant sous Windows, l'intérêt d'utiliser un tel produit pour une architecture distribuée paraît faible. DCOM n'offre en effet des bindings, ou liens, que vers Visual C++, Visual Basic et Visual J++, qui sont tous des produits 100% compatibles Microsoft. La vocation majeure des produits Microsoft étant de piéger le consommateur, DCOM se trouve clairement à l'opposé de ce que l'on peut attendre d'une architecture distribuée ouverte.
Pour conclure sur le sujet, on peut dire que de DCOM se dégage une impression de non globalité des concepts. De plus, DCOM risque de mal évoluer face aux nouveaux besoins des architectures distribuées, puisqu'il traîne le boulet COM. Par contre, on peut être sûr que Microsoft fera tout pour faire durer son produit. Ainsi DCOM et ses évolutions sont encore là pour longtemps.
Les Entreprise Java Beans ( EJB )
C'est une spécification d'architecture à base de composants distribués permettant la réalisation d'applications métiers critiques, tenant la charge, sécurisées, systèmes-indépendantes et basées sur des composants réutilisables ( côté serveur ) sur la plate-forme JAVA.
Les développeurs d'applications peuvent enfin se concentrer sur le développement de la logique métier sans se soucier de la logique technique. L'architecture délègue cette tache aux serveurs applicatifs, compatibles EJB et commercialement disponibles.
C'est un environnement d'execution distribué pour java intégrant un moniteur transactionnel et un support de persistance.
Les EJBs proposent un modèle d'application structurant d'un point de vue logiciel. Ce modèle prend en compte deux types d'EJBs
L'emploi des EJBs permet de réduire la complexité de développement et de rendre les composants développés plus facilement réuilisables. Lorsqu'une apllication est développée et déployé sur des middlewares c'est le serveur EJB qui gère l'accès a ces serveurs d'infrastructre. Ceci isole les comosants applicatifs du middleware sous-jacent pour les rendre indépendants l'un de l'autre.
Le serveur EJB est un gestionnaire de ressources qui gère des conteneurs d'EJB et offre des interface d'accès a des services techniques. Il fournit un ensemble d'interfaces et de services pour les conteneurs comme la gestion transactionnelle et la gestion de persistance.
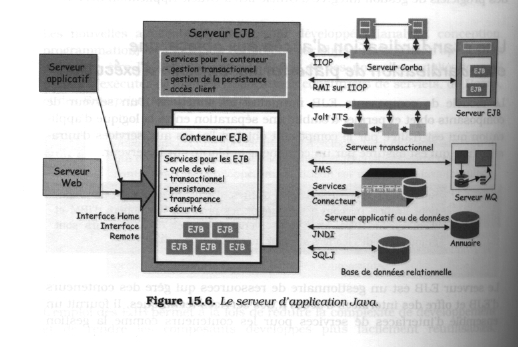
Serveur EJB.
Les EJB sont basés sur RMI (Remote Method Invocation). C'est une API Java permettant de manipuler des objets distants (c'est-à-dire un objet instancié sur une autre machine virtuelle, éventuellement sur une autre machine du réseau) de manière transparente pour l'utilisateur, c'est-à-dire de la même façon que si l'objet était sur la machine virtuelle (JVM) de la machine locale.
Ainsi un serveur permet à un client d'invoquer des méthodes à distance sur un objet qu'il instancie. Deux machines virtuelles sont donc nécessaires (une sur le serveur et une sur le client) et l'ensemble des communications se fait en Java.
On dit généralement que RMI est une solution "tout Java", contrairement à la norme Corba de l'OMG (Object Management Group) permettant de manipuler des objets à distance avec n'importe quel langage. Corba est toutefois beaucoup plus compliqué à mettre en oeuvre, c'est la raison pour laquelle de nombreux développeurs se tournent généralement vers RMI.
A partir de Java 2 version 1.3, les communications entre client et serveur s'effectuent grâce au protocole RMI-IIOP (Internet Inter-Orb Protocol), un protocole normalisé par l'OMG (Object Management Group) et utilisé dans l'architecture CORBA. Le principal avantage de RMI-IIOP est qu'il utilise IIOP comme protocole de communication. Ceci lui permet d'interagir avec les autres ORBs et communiquer avec des composants CORBA qui ne sont pas forcément écrits en Java.
Comme en RMI, les interfaces des objets distribués sont à décrire en Java. Les programmeurs doivent cependant suivre quelques restrictions lors de la définition de ces interfaces, de manière à assurer la compatibilité avec CORBA. Toutes ces interfaces décrites en Java sont traduisibles en IDL, grâce à la nouvelle version du compilateur rmic, et donc exploitables par toute plate-forme CORBA.
La manipulation inverse, à savoir générer des interfaces Java à partir de fichiers IDL, peut être réalisée automatiquement par le compilateur idlj. Écrit en Java, idlj est utilisable sur toutes plate-formes. Ce compilateur vient remplacer l'ancien idltojava qui était uniquement disponible pour quelques plates-formes, car écrit en code natif.
RMI-IIOP est donc facile d'utilisation, parfaitement intégré à Java et ouvert, car compatible CORBA. Ainsi, même s'il s'avère un peu léger face aux ORBs industriels, RMI-IIOP peut être considéré comme un bon choix de plate-forme de communication pour objets distribués.
Comparatif entre EJB et CORBA.
|
EJB
|
CORBA
|
|
composant
|
objet
|
|
nécessite
plus de service: transactionnel, persistance..
|
|
|
indépendant
de la plate-forme
|
indépendant
de la plate-forme et du langage
|
|
réingénierie
de l'existant plus facile
|
|
|
RMI-IIOP
|
IIOP
|
|
passage d'objet
valeur plus facile
|
Avec le développement d'internet mais aussi des extranet d'entreprise va imposer les architecures n-tier. Nous avons constaté que de nombreux outils étaient donnée aux développeur pour réaliser ce type d'application( que ce soit dans le monde Microsoft ou le monde Unix ). Le schéma ci-dessous montre l'exemple d'une architecture 3 tier basé sur les technologies JAVA, les EJB et différents middleware. Cet exemple regroupe une grande partie des outils que nous avons étudiés au cours de notre étude.
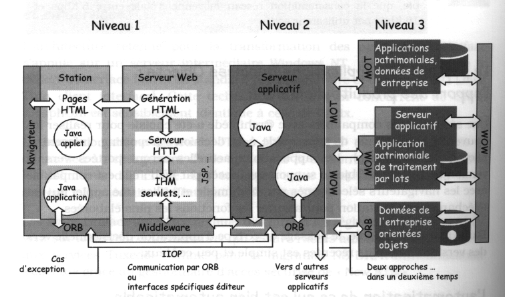
Architecture 3-tier
Livres
Liens internet
Autre