
Buffers et représentation des données
Cours 1
Concept de base
Tout ce qui est échangé sur le réseau n'est qu'une suite d'octets qui n'a aucun sens a priori. --- Matrix
Comme les machines qui communiquent peuvent avoir des processeurs différents, des OS différents et utiliser des langages de programmation différents, il n'y a aucune convention a priori.
C'est le protocole qui fixe le sens (sémantique) des octets.
Exemple
Que représentent les octets 61 E2 82 AC
- Un nombre ou des nombres : taille en octets, endianness, signé vs non-signé ?
- Une ou des chaînes de caractères : jeu de caractères, taille ?
- Une image ...
61 E2 82 AC
61 E2 82 ACTaille :
short (2 octets),
int (4 octets) et
long (8 octets)
Endianness :
- BigEndian : octet de poids fort en premier
61 E2 82 AC→ 1642234540 - LittleEndian : octet de poids faible en premier
61 E2 82 AC → AC 82 E2 61 → 2894258785
Signé vs Non-Signé :
AC 82 E2 61 (non-signé) → 2894258785
AC 82 E2 61 (signé) → -1400708511
61 E2 82 AC
Une chaîne de caractères ?
En ASCII (7 bits), ces octets sont invalides : "a???"
En ISO-8859-1, ces octets représentent "aâ ¬"
En UTF-8, ces octets représentent "a€"
Jeux de caractères
Un caractère est un symbole, qui peut être représenté de différentes manières.
En Java, en interne, le type primitif char
permet de représenter ces symboles sur 2 octets (16 bits) dans le jeu de
caractères Unicode (UTF-16).
Il existe de nombreux jeux de caractères (ASCII, UTF-8, ISO-8859-1...)
61 E2 82 AC
61 E2 82 ACPour traiter des octets comme des caractères, il faut impérativement connaître le jeu de caractères (charset ) !
- En ASCII (7 bits), ISO-8859-1 ou UTF-8
61'a' - En ASCII (7 bits) :
E2 - En ISO-8859-1 :
E2'â' - En UTF-8:
E2 - Mais en UTF-8 :
E2 82 AC'€'
En Java
En Java, l'approche historique pour manipuler des octets était d'utiliser des
tableaux de type byte[]
Problème de performance : la représentation de byte[]
Problème résolu par java.nio en autorisant des implémentations plus performantes.
Pour ce cours, on interdit les
byte[]
java.nio : "nouvelles" entrées-sorties (1.4)
Gestion mémoire découplée entre système et JVM (performance)
(Input/Output)Stream deviennent des Channel
ByteBuffer au lieu des tableaux byte[] ;
Charset formalisent l'encodage des caractères.
On manipule ces classes sans connaître leur implémentation (plate-forme dépendante).
java.nio.ByteBuffer
Même concept qu'un tableau d'octets :
zone contiguë de bytes de taille fixe (capacity)
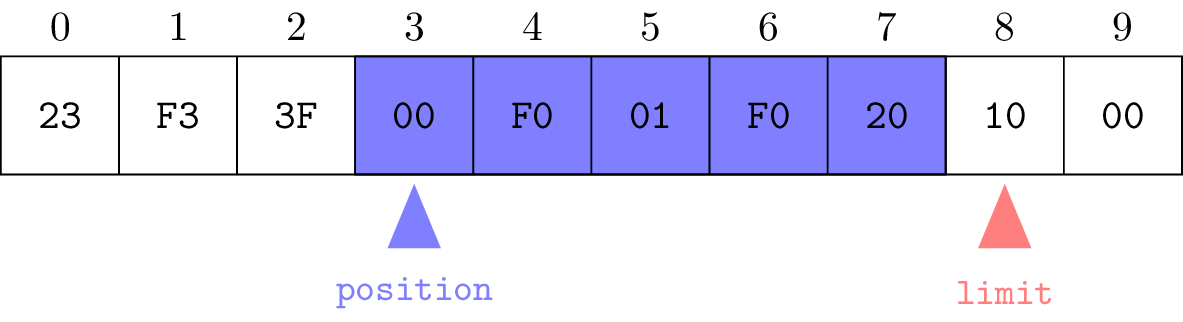
On utilise la notion de zone de travail définie entre :
position = prochain indice à accéder et
limit = premier indice "interdit".
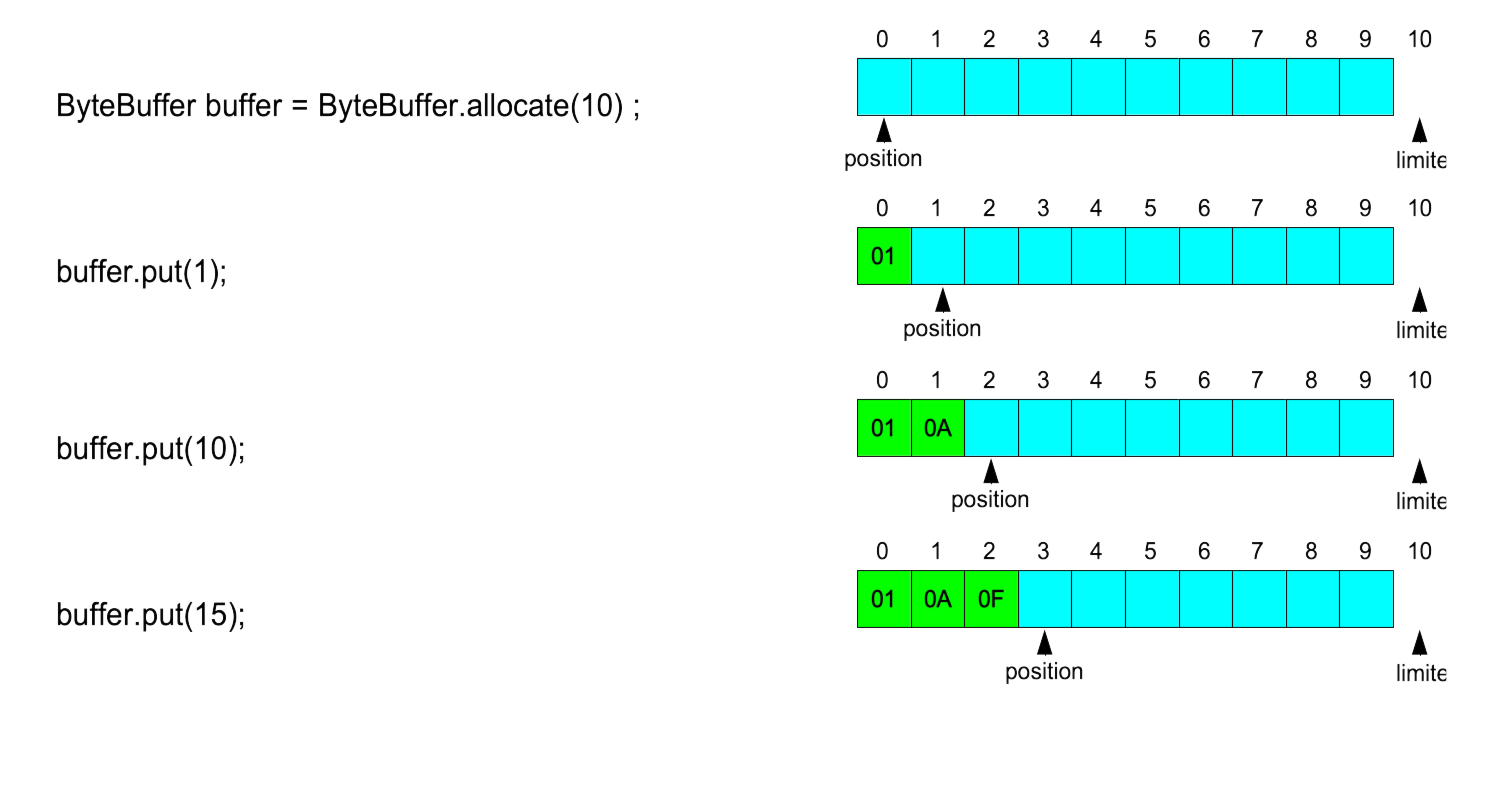
Création d'un ByteBuffer
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
La méthode factory ByteBuffer.allocate(int capacity)
crée un ByteBuffer de taille capacity.
La postion est à 0 et la limit est à
capacity.
La mémoire est gérée par le Garbage Collector de Java.
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
Identique à la méthode ci-dessus mais la mémoire n'est pas gérée
par le Garbage Collector (mais par le système).
Les entrées/sorties sont plus performantes mais l'allocation et la libération beaucoup plus lentes.
Dogme : On réserve allocateDirect()
aux ByteBuffer qui "vivent" pendant toute la durée du programme.
Accès au ByteBuffer
L'accès est relatif à la position courante :
put(b) écrit l'octet b à la position couranteget() lit et retourne l'octet à la position couranteLes deux font avancer la position courante (comme dans un flot).
Si la position est en dehors de la zone de travail, une exception est levée :
BufferOverflowException ou BufferUnderflowException
Utilisation d'un ByteBuffer
La zone de travail diminue au fur et à mesure qu'on écrit.
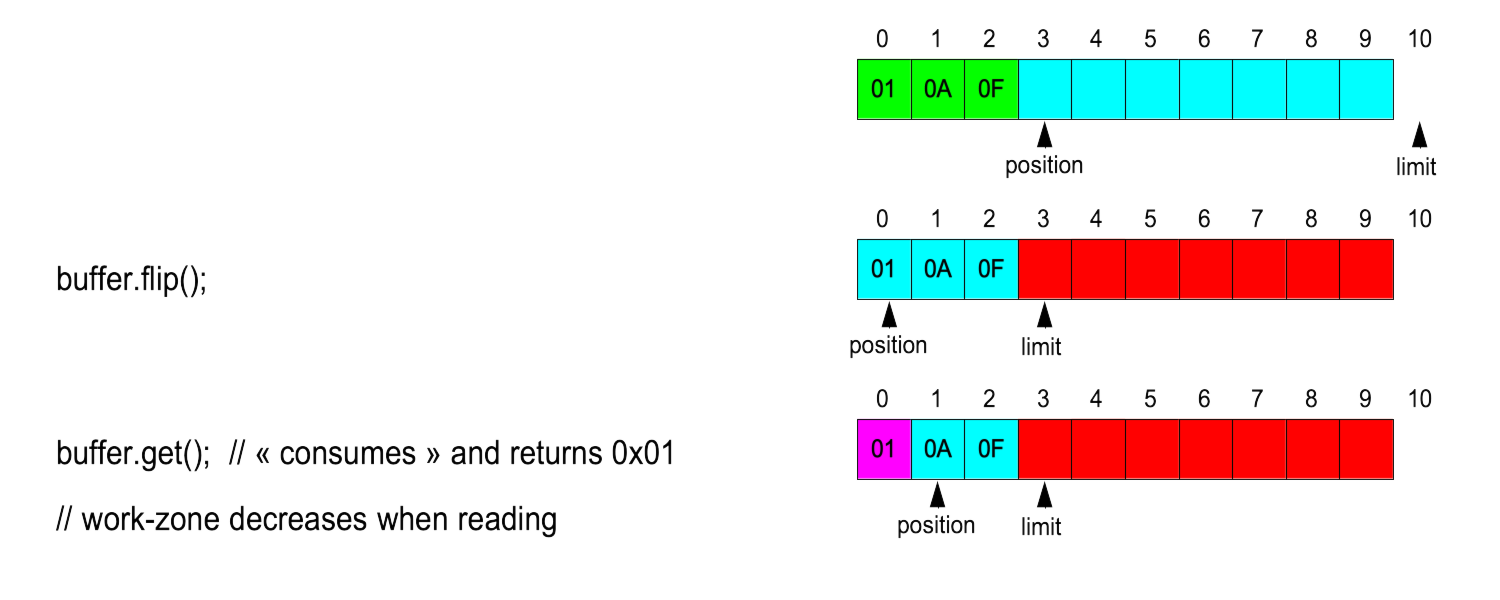
Méthode flip
Pour pouvoir relire ce qui vient d'être écrit : limite := position et position := 0
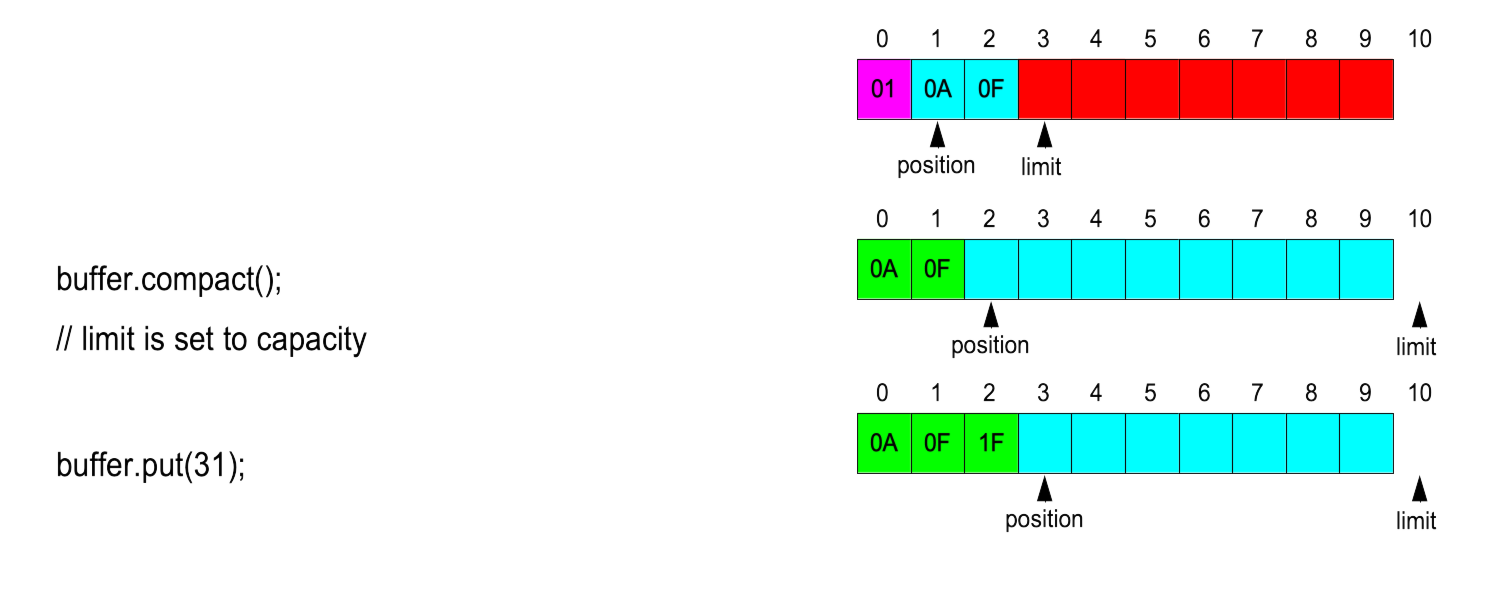
Méthode compact
Pour pouvoir recaler au début ce qui n'a pas été "consommé"
et se mettre à nouveau en position d'écrire dans le buffer :
D'autres méthodes utiles
remaining() donne la taille de la zone de travail,
c'est à dire le nombre de fois où on peut accéder (par get ou put)hasRemaining() retourne true si on peut accéderposition() donne la position couranteposition(int pos) fixe la position courantelimit() donne la limite actuellelimit(int pos) fixe la limiteclear() remet le buffer "comme neuf"Méthodes pour les types primitifs
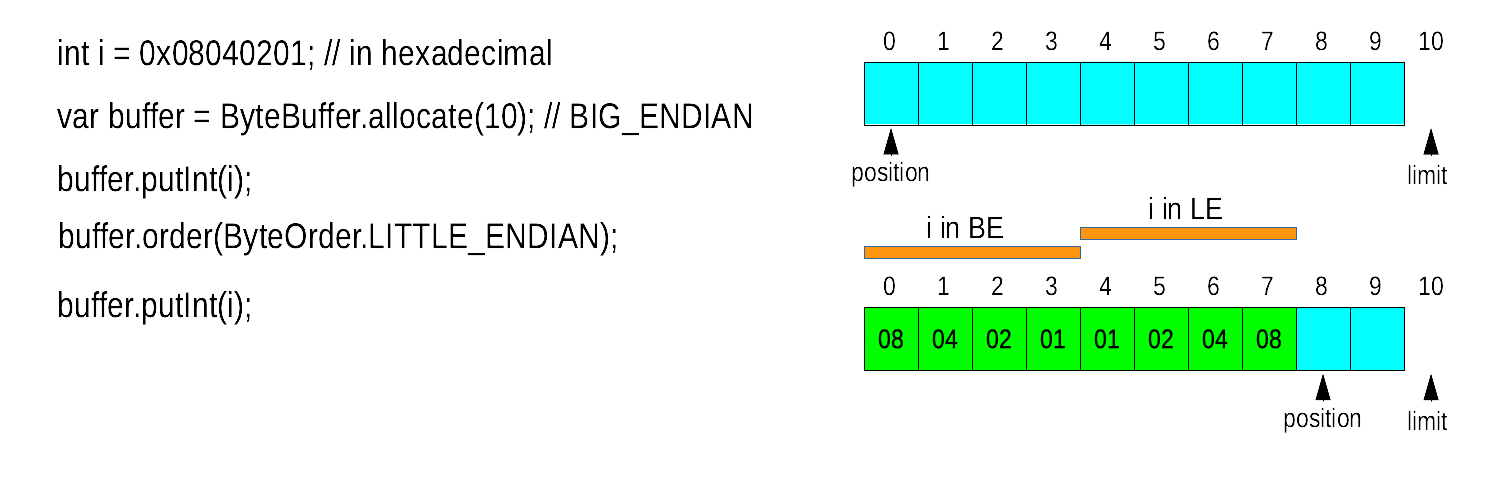
putInt() écrit les 4 octets d'un int au début de la zone de travail et la réduitgetInt() lit les 4 octets d'un int au début de la zone de travail et la réduitputLong()
et getLong() pour 8 octets du long.
putShort()
et getShort() pour 2 octets du short.
Question : que fait buffer.putInt() en mémoire ?
L'endianess
L'ordre de représentation des entiers en mémoire peut être :

java.nio.ByteOrder
L'ordre d'un ByteBuffer est par défaut
BigEndian à la création, mais peut être modifié
par order(ByteOrder)
Les autres tampons sont par défaut créés avec l'ordre natif
Encodage et décodage
Un jeu de caractères est l'association d'un code (sur un ou plusieurs octets) pour chacun des caractères de ce jeu.
L'encodage est la traduction d'une suite de caractères (symboles) en une suite d'octets.
Le décodage est l'opération inverse, d'une suite d'octets en une suite de caractères.
Les deux opérations n'ont de sens que relativement à un jeu de caractères.
java.nio.charset.Charset
Un objet Charset représente un jeu de caractères :
Charset charset = Charset.forName("UTF-8"); ou
Charset UTF8 = StandardCharsets.UTF_8;
Des méthodes simples permettent d'encoder ou de décoder dans ce jeu de caractères :
ByteBuffer buffer = charset.encode(String s)CharBuffer cb = charset.decode(ByteBuffer buffer)Dans ce cours, on n'autorisera que ces deux méthodes.
D'autres méthodes plus complètes sont accessibles via les classes
CharsetEncoder et CharsetDecoder.
Exemple d'encodage
Selon le jeu de caractères utilisé et le caractère encodé, le nombre d'octets qui le représente est variable.
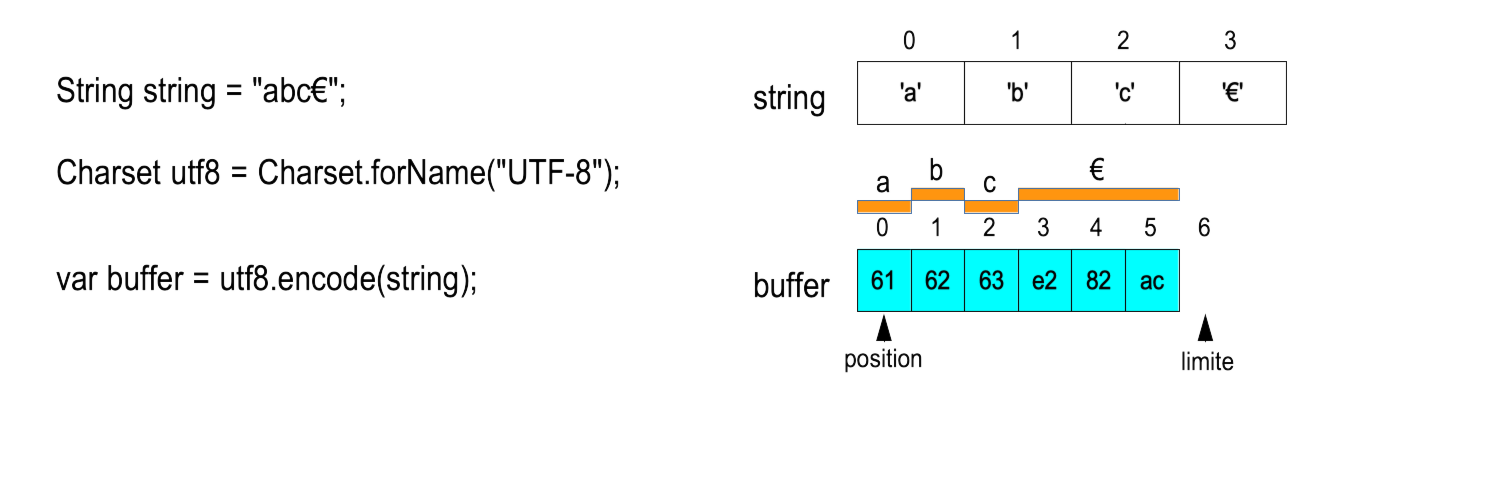
Attention : encode crée un nouveau buffer possiblement plus grand que la zone de travail !
Il faut être sûr d'avoir l'intégralité des octets pour pouvoir décoder.
FileChannel
Un FileChannel permet de lire et d'écrire des octets à partir d'un fichier.
Nous allons nous en servir pour nous familiariser avec les ByteBuffer en attendant d'avoir vu UDP et TCP.
Path path = Path.of("~/test.txt");
// ouverture en lecture
try (FileChannel fc = FileChannel.open(path, StandardOpenOption.READ)) {
....
}
// ouverture en écriture avec écrasement
try(FileChannel fc = FileChannel.open(path,
StandardOpenOption.CREATE,
StandardOpenOption.WRITE,
StandardOpenOption.TRUNCATE_EXISTING)){
....
}
Lecture
fc.read(ByteBuffer buffer) lit depuis le fichier, via le
canal fc, des octets qu'elle
stocke dans la zone de travail de buffer.
La méthode
read retourne le nombre d'octets lus ou -1 si
le canal est fermé.
Même si le fichier contient plus d'octets que le ByteBuffer,
il n'y a pas de garantie que le buffer soit rempli intégralement.
Par défaut, la lecture est bloquante, i.e., read bloque jusqu'à avoir lu au moins un octet, s'il y a la place dans le buffer buffer.
Écriture
L'appel à fc.write(ByteBuffer buffer) écrit les
buffer.remaining() octets de buffer
dans le canal fc.
Par défaut, l'écriture est bloquante, i.e., write
retourne quand tous les octets ont été écrits.
Exemple (1/3)
On cherche à réaliser un programme qui :
- prend un nom de fichier en argument,
- lit des
intau clavier et les écrit dans le fichier en BigEndian.
Pour simplifier, dans un premier temps, on va écrire les int au fur et à mesure qu'ils sont lus.
NB : ce n'est pas efficace, il vaudrait mieux grouper les écritures.
Exemple (2/3)
var path = Path.of(args[1]);
var buffer = ByteBuffer.allocate(Integer.BYTES); // 4 bytes
try(var channel = FileChannel.open(path, StandardOpenOption.CREATE,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
var scanner = new Scanner(System.in)) {
while (scanner.hasNextInt()) {
buffer.putInt(scanner.nextInt());
buffer.flip();
channel.write(buffer);
buffer.clear();
}
}
Que faire de l'IOException levée par FileChannel.open et FileChannel.write?
Exemple (3/3)
Plus efficace : on prend un gros ByteBuffer que l'on remplit avec les
int. Quand il n'y a plus assez de place dans le ByteBuffer,
on écrit son contenu dans le fichier avant de continuer.
var path = Path.of(args[1]);
var buffer = ByteBuffer.allocate(BUFFER_SIZE);
try(var channel = FileChannel.open(path, StandardOpenOption.CREATE,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
var scanner = new Scanner(System.in)) {
while (scanner.hasNextInt()) {
if (buffer.remaining() < Integer.BYTES){
buffer.flip();
channel.write(buffer);
buffer.clear();
}
buffer.putInt(scanner.nextInt());
}
buffer.flip();
channel.write(buffer);
}