Buffers and data representation
Lecture 1
Basic concept
Everything that is exchanged through the network is a sequence of bytes which has no meaning in the absolute. --- Matrix
As the different machines that communicate have different processors, OS and programming languages, there is no common ground.
It is the protocol that fixes the meaning of the bytes.
Example
What do the bytes 61 E2 82 AC represent (in hexadecimal) ?
- A single number or several numbers : size in bytes ?
- Endianness, signed vs unsigned ?
- One or several strings : charset, size?
- An image ...
61 E2 82 AC
Size:
short (2 bytes),
int (4 bytes) et
long (8 bytes)
Endianness
- BigEndian: most significant byte first
61 E2 82 AC→ 1642234540 - LittleEndian: least significant byte first
AC 82 E2 61 → 2894258785
Signed vs Unsigned
AC 82 E2 61 (unsigned) → 2894258785
AC 82 E2 61 (signed) → -1400708511
Hexadecimal, signed vs unsigned
At OS or programmation level, we consider byte (8 bits) as the atomic element.
Hexadecimal : 61 E2 82 AC Binary : 0110 0001 1110 0010 1000 0010 1010 1100 Decimal : 97 226 130 172
When signed, integers are represented in Two's complements (0 is only positive)
Unsigned Signed
Hexadecimal : AC AC
Binary : 1010 1100 1010 1100
Decimal : 172 -84
https://en.wikipedia.org/wiki/Signed_number_representations#Two's_complement
Endianness
- BigEndian: most significant bit first (stored at the smallest index in memory)
- LittleEndian: least significant bit first (stored at the smallest index in memory)
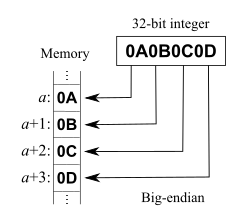
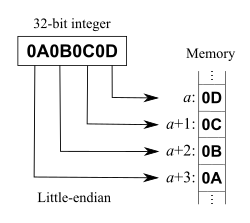
61 E2 82 AC
A string ?
In ASCII (7 bits), only the first by is valid: "a???"
In ISO-8859-1, these bytes represent "aâ ¬"
In UTF-8, these bytes represent "a€"
Charset
A character is a symbol which in Java is represented by the primitive type char.
A charset is a mapping between characters and sequences of bytes.
There exist numerous charsets (ASCII, UTF-8, ISO-8859-1...)
61 E2 82 AC
To go from bytes to characters, we need a charset.
In ASCII (7 bits), ISO-8859-1 or UTF-8 61
represent 'a'
In ASCII (7 bits): E2 does not correspond to any character.
In ISO-8859-1: E2 represent 'â'
In UTF-8: E2 is not associated to any character.
But in UTF-8: E2 82 AC represents '€'
In Java
Historically, Java manipulated sequences of bytes using byte arrays byte[].
Performance problem : the internal representation of byte[] is fixed by the language specification.
Solved in java.nio by using ByteBuffer which allow for more efficient implementations.
Throughout this course, we forbid the use of
byte[].
java.nio: the new inputs/outputs (1.4)
Possibility of handling memory outside the Garbage Collector (performance)
Channel objects
ByteBuffer instead of byte[]
Charset objects are introduced to represent charsets.
Abstract classes are used to hide platform-dependent implementations.
(1): here, Streams means raw data (bytes) streams and not for java.util.stream.Stream
java.nio.ByteBuffer
Essentially an array of bytes:
a sequence of bytes of fixed size (capacity)
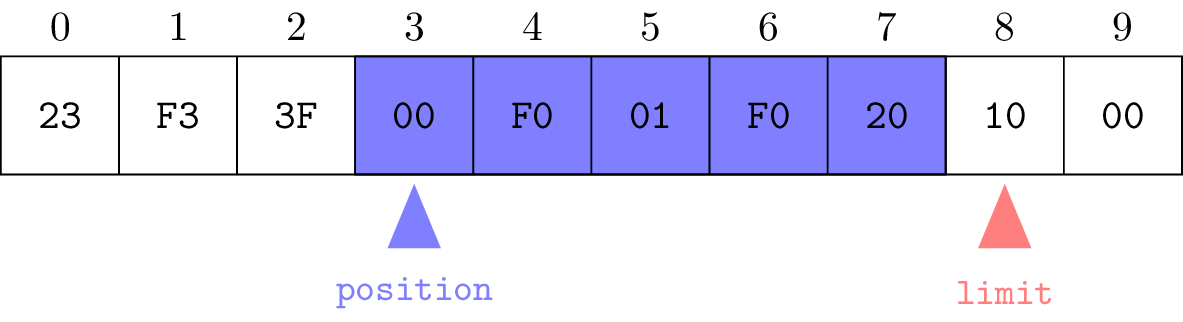
Notion of work-zone between two indices
position = first index in the zone
limit = first index outside of the zone
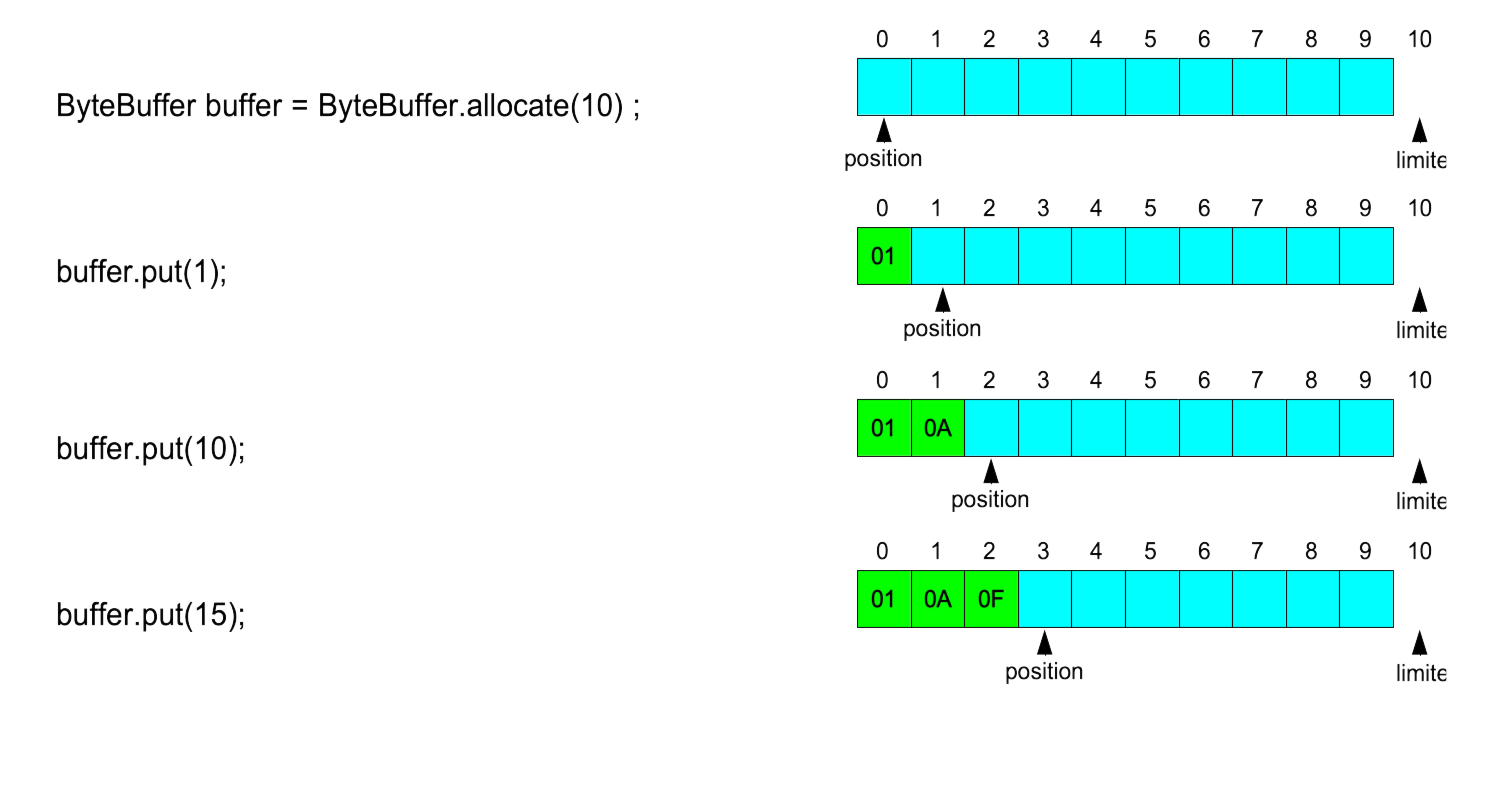
Creating a ByteBuffer
ByteBuffer bb = ByteBuffer.allocate(1024);
The factory method ByteBuffer.allocate(int capacity)
creates a ByteBuffer of size capacity.
The postion is set to 0 and the limit to the
capacity.
This object is managed by Java's Garbage Collector.
ByteBuffer bb = ByteBuffer.allocateDirect(1024);
Same result as the method above except the object is not handled by the Garbage Collector, but rather by the system.
IO are more efficient but allocation/deallocation are much slower.
Dogma: We reserve allocateDirect()
for ByteBuffer that are used throughout the whole duration of the program.
Acessing a ByteBuffer
Access is relative to the current position:
put(b) write a b at the current position,get() reads and returns the byte at the current position. both calls increase the current position by one (as in a stream)
⇒ it reduces by one the work-zone.
If the work-zone is empty, an exception is raised:
BufferOverflowException or BufferUnderflowException
Read-mode or write-mode
Conceptually, a buffer is:
put() calls⇒ its work-zone contains useless data that will be overwritten
get() calls⇒ its work-zone contains useful data to be read
You must carefully use specific methods to change a buffer's mode
Using a ByteBuffer
An allocated buffer is in write-mode:
Flip
To switch from write-mode to read-mode:
limit := position and position := 0
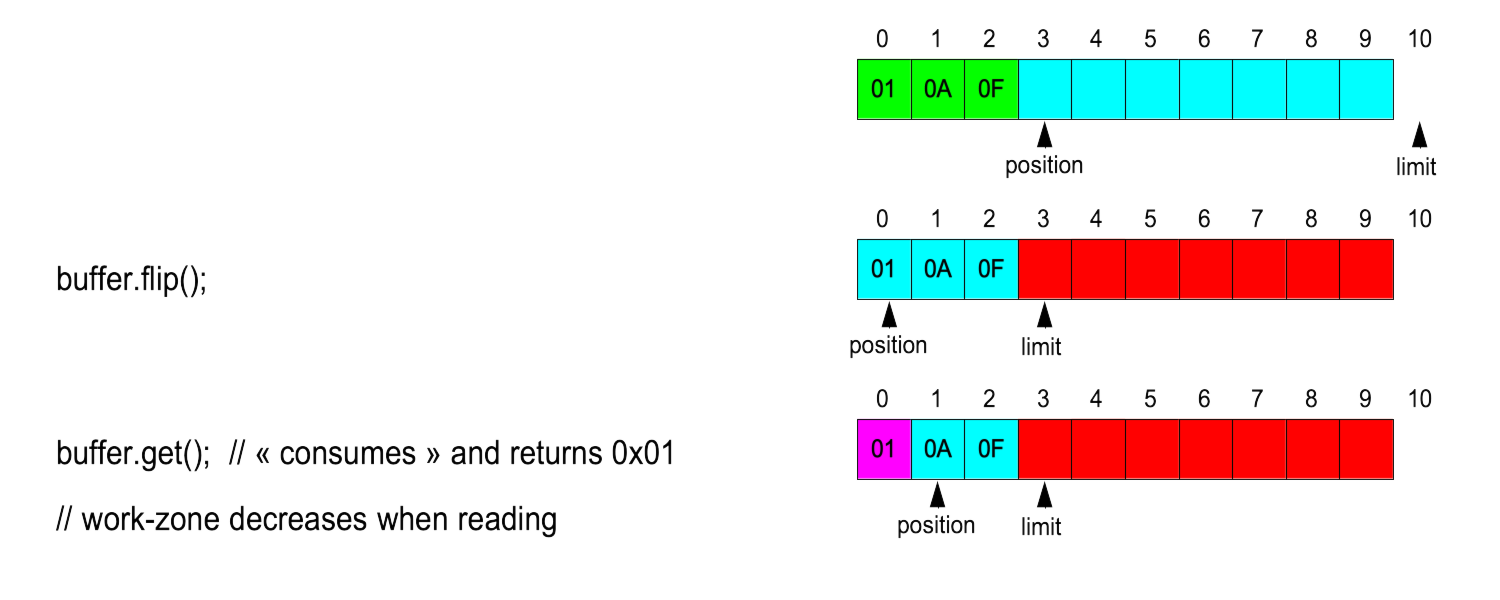
Compact
To switch in to write-mode (and add new bytes at the end of the current work-zone
without losing those not yet read):
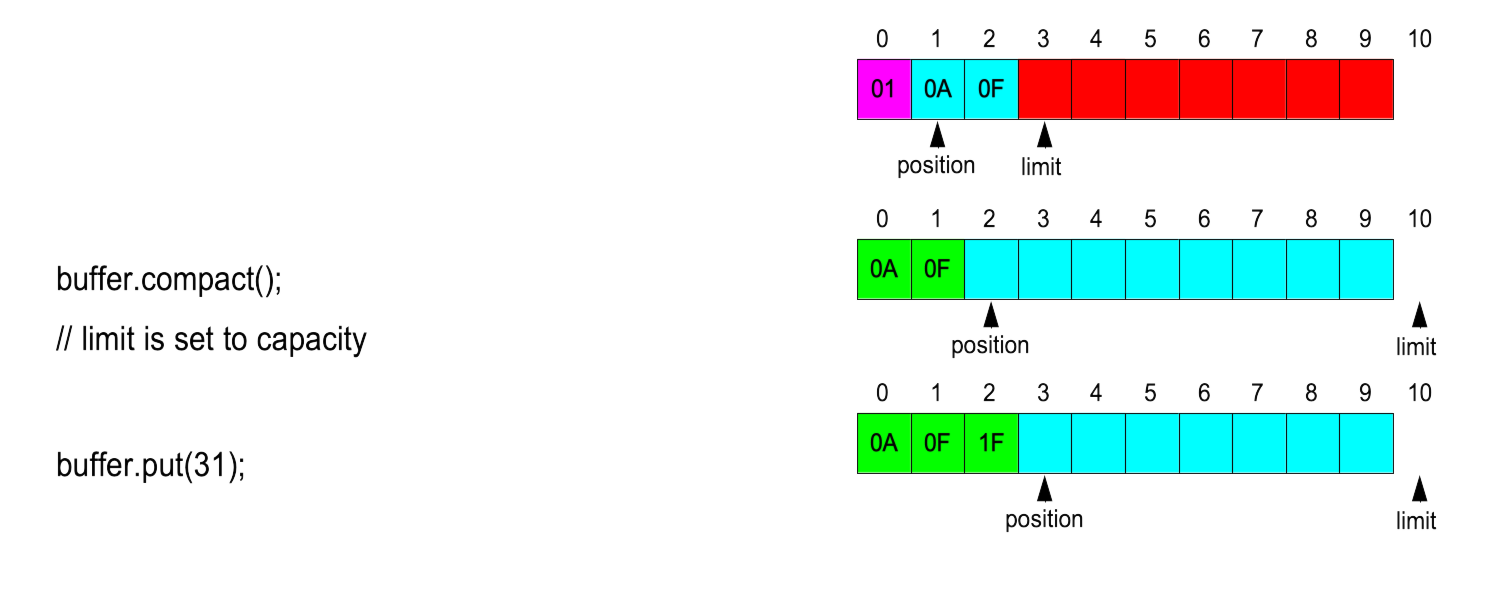
Other useful methods
remaining() returns the size of the work-zonehasRemaining() returns true if the work-zone is non-emptyposition() gives the value of the position indexposition(int pos) sets the position indexlimit() gives the limit indexlimit(int pos) sets the limit indexclear() sets position to 0 and limit to capacityMethods for primitive types
putInt() writes the 4 bytes of an int at the beginning of the work-zone and reduces itgetInt() reads the 4 bytes of an int at the beginning of the zone and reduces itputLong()
and getLong() for the 8 bytes of a long.
putShort()
and getShort() for the 2 bytes of a short.
Question: which bytes does bb.putInt(1) write in bb ?
Endianess
The byte-order in memory for shorts,ints and longs can be:

java.nio.ByteOrder
ByteOrder.nativeOrder() give the native byte-order of the plateform.
By default, the order of a ByteBuffer is
BigEndian but it can be modified using order(ByteOrder)
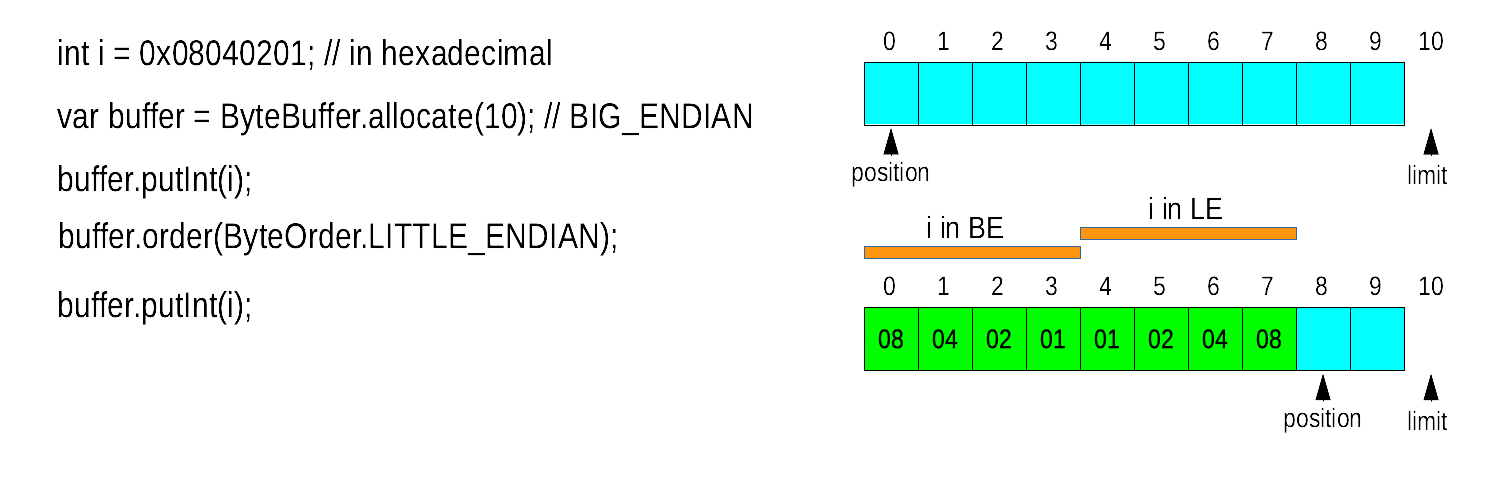
Encoding and decoding
A charset gives a code (over one or several bytes) for each character in this charset.
Encoding translates a sequence of characters into a sequence of bytes.
Decoding is the inverse operation, going from a sequence of bytes to a sequence of characters.
Obviously, encoding/decoding only have meaning relative to a charset.
java.nio.charset.Charset
Represents a set of characters
Charset charset = Charset.forName("UTF-8"); or
Charset charset = StandardCharsets.UTF_8;
It provides simple methods to encode and decode.
ByteBuffer bb = charset.encode(String s)CharBuffer cb = charset.decode(ByteBuffer bb)In this course, we only alllow these two methods.
More efficient methods can be accessed via
CharsetEncoder and CharsetDecoder
Example of decoding
Depending on the charset, a character may be encoded by one, two, three... bytes.
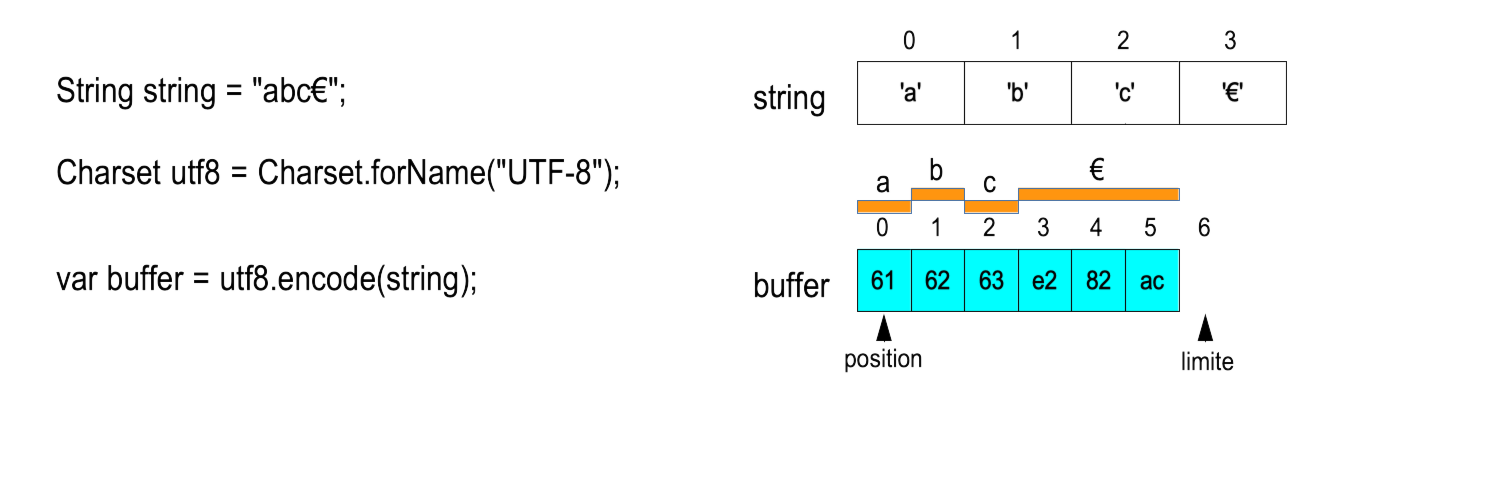
We must be sure of having all of the bytes before decoding.
FileChannel
A FileChannel allows to read and write raw bytes from/to a file.
We are going to use them to play with ByteBuffer before introducing UDP and TCP.
Path path = Paths.get("~/test.txt");
// open in read-mode
try (FileChannel fc = FileChannel.open(path, StandardOpenOption.READ)) {
....
}
// open in write-mode
try(FileChannel fc = FileChannel.open(path,
StandardOpenOption.CREATE,
StandardOpenOption.WRITE,
StandardOpenOption.TRUNCATE_EXISTING)){
....
}
Reading
int fc.read(ByteBuffer bb) reads at most bb.remaining() bytes from the channel fc and stores them in the buffer bb
read() returns the number of bytes read, or -1 if the channel is closed.
Even if the file contains more bytes than the buffer work-zone, there is no guarant that the buffer will be completely filled by a single call.
By default, reading is blocking, i.e., read() blocks until at least one byte is read.
Writing
int fc.write(ByteBuffer bb) writes bb.remaining()
bytes in the channel fc, taken from the work-zone of the buffer bb
By default, writing is blocking, i.e., write() returns when all bytes have been written (it returns this number).
Example (1/3)
We want to write a program that:
- takes a filename as argument,
- while there is input: reads integers (int) from the keyboard and writes the corresponding 4 bytes in the file in BigEndian.
To simplify, we will first write these int in the file as soon as they are read.
NB: not efficient, write should be grouped
Example (2/3)
Path path = Paths.get(args[1]);
ByteBuffer buff = ByteBuffer.allocate(Integer.BYTES); // 4 bytes
try(FileChannel fc = FileChannel.open(path, StandardOpenOption.CREATE,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
Scanner scan = new Scanner(System.in)) {
while (scan.hasNextInt()) {
buff.putInt(scan.nextInt());
buff.flip();
fc.write(buff);
buff.clear();
}
}
What do we do with the IOException raised by FileChannel.open and FileChannel.write?
Example (3/3)
More efficient, we take a large ByteBuffer that we fill with the
int. When the buffer is full, we write it to the file before going on.
Path path = Paths.get(args[1]);
ByteBuffer buff = ByteBuffer.allocate(BUFFER_SIZE);
try(FileChannel fc = FileChannel.open(path, StandardOpenOption.CREATE,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
Scanner scan = new Scanner(System.in)) {
while (scan.hasNextInt()) {
if (buff.remaining()<Integer.BYTES){
buff.flip();
fc.write(buff);
buff.clear();
}
buff.putInt(scan.nextInt());
}
buff.flip();
fc.write(buff);
}